|
The 400
requirements/questions that were filled out in the spreadsheets associated with
the Domain Template were termed the atomic requirements/questions because they
were formed as questions using terms that would be familiar to power system
engineers. These atomic requirements were then analyzed against the
technologies and services in spreadsheets and the resulting relationships were
imported into the UML model in order to provide a complete integrated object
model.
However, these
atomic requirements were focused on responses by power system engineers to
reflect the requirements for individual steps within individual power system
functions, and as such were not easily usable to address more global
requirements. Therefore these 400 atomic requirements/questions were combined
into 63 aggregated requirements that more clearly identified the architectural
requirements using more global terms. Examples of this mapping from atomic
requirements/questions to aggregated requirements are:
·
The atomic requirements/questions “Are the distances between communicating
entities a few to many miles?” plus “Location
of information producer (source of data) is outside substation, or another
corporation or a customer site while the Location of the information receiver
is outside a substation, or another corporation or a different customer site”
became the aggregated requirement to “Support
interactions across widely distributed sites”
·
The atomic requirement/question “Eavesdropping: Ensuring confidentiality,
avoiding illegitimate use of data, and preventing unauthorized reading of data,
is crucial” plus “Information theft:
Ensuring that data cannot be stolen or deleted by an unauthorized entity is
crucial” became the aggregated requirement “Provide Confidentiality Service (only authorized access to information,
protection against eavesdropping)”
The final “link”
in the analysis was the correlations between IntelliGrid Architecture Environments and the 500+
standard technologies, services, and best practices. Two approaches were used:
the atomic requirements approach and the aggregated requirements approach. Both
approaches were used because the atomic requirements were the smallest atomic
(i.e. indivisible) capability assessed during the analysis of the Use Cases,
while the aggregated requirements were clearest to present to users.
Therefore, the
aggregated requirements were used to define the characteristics of the 20 IntelliGrid Architecture
Environments. These Environments, based on their defining aggregated
requirements, were then linked to the standard technologies, common services,
and best practices, using expert opinion from IntelliGrid Architecture team’s combined deep
and broad experience in the utility and communications industries. Although
this approach might have permitted some bias, it was believed that the checks
and balances of the different experiences of the team members, combined with
long, in depth discussions of the different technologies, have prevented any
substantive bias.
This section
describes the aggregated requirements. Each requirement is assigned with a
unique identifier to achieve traceability. The identification string starts
with “REQ” and then is followed by an abbreviation that denotes the four
categories:
·
CR for configuration requirement
·
QOS for quality of service requirement
·
SR for security requirement
·
DM for data management
The identifier
ends with “-” and a sequence number.
<REQ CR-1>
Provide point-to-point interactions between two entities.
This requirement
reveals the need for a request/reply interaction mechanism. In this case a client connects to a server
and requests the server to take some action.
However, it should be noted that as the IntelliGrid Architecture is focused on
the integration of loosely coupled systems, what the server does as a result of
this request is unknown by the client.
While the server is required to notify the client that the request has
been received, confirmation of the request being carried out is done by the
server via a publication of a change event.
<REQ CR-2>
Support interactions between a few "clients" and many
"servers"
This requirement
reveals the need for a platform level service for discovery of distributed
components as well as their status. As
systems become larger and more complex, it becomes more and more important to
have an automated means to discover what services are available where.
<REQ CR-3>
Support interactions between a few "servers" and many
"clients"
This requirement
reveals the need for a publish/subscribe-oriented services whereby a server can
simultaneously notify many clients of a change.
A publish/subscribe mechanism facilitates the decoupling of servers from
clients so that clients may be created and destroyed without requiring any
action of the part of a server.
<REQ CR-4>
Support peer to peer interactions.
This requirement
reveals the need for a collection of services is made available to other
components.
<REQ CR-5>
Support interactions within a contained environment (e.g. substation or control
center)
This requirement
reveals the need for a technology independent design that can to a variety of
environments. Each environment has
unique characteristics that determine what technology is used to realize the
technology independent architecture.
<REQ CR-6>
Support interactions across widely distributed sites.
This requirement
reveals the need for a transport neutral set of interfaces where the
distribution of communication components is not exposed at the interface. In this way, the actual protocol used to
remote a service interface is not known by components. This minimizes reconfiguration as components
are moved to different network having their own transport requirements.
Hiding transport
specifics from application components do not mean that transport services do
not have to be managed, but only that they are managed independently of
application component design. Transport
needs to be managed within a deployment scenario in real time using enterprise
management systems. Enterprise
management services can be found below.
<REQ CR-7>
Support multi-cast or broadcast capabilities
See CR – 3.
<REQ CR-8>
Support the frequent change of configuration and/or location of end devices or
sites
See CR – 6.
<REQ CR-9>
Support mandatory mobile communications
See CR – 6.
<REQ QOS-1>
Provide ultra high speed messaging (short latency) of less than 4 milliseconds
<REQ QOS-2>
Provide very high speed messaging of less than 10 milliseconds
<REQ QOS-3>
Provide high speed messaging of less than 1 second. Provide medium speed
messaging on the order of 10 seconds
<REQ QOS-4>
Support contractual timeliness (data must be available at a specific time or
within a specific window of time)
<REQ QOS-5>
Support ultra high availability of information flows of 99.9999+ (~1/2 second)
<REQ QOS-6>
Support extremely high availability of information flows of 99.999+ (~5
minutes)
<REQ QOS-7>
Support very high availability of information flows of 99.99+ (~1 hour)
<REQ QOS-8>
Support high availability of information flows of 99.9+ (~9 hours)
<REQ QOS-9>
Support medium availability of information flows of 99.0+ (~3.5 days)
<REQ QOS-10>
Support high precision of data (< 0.5 variance)
<REQ QOS-11>
Support time synchronization of data for age and time-skew information
<REQ QOS-12>
Support high frequency of data exchanges
<REQ SR-1>
Provide Identity Establishment Service (you are who you say you are)
<REQ SR-2>
Provide Authorization Service for Access Control (resolving a policy-based
access control decision to ensure authorized entities have appropriate access
rights and authorized access is not denied)
<REQ SR-3>
Provide Information Integrity Service (data has not been subject to
unauthorized changes or these unauthorized changes are detected)
<REQ SR-4>
Provide Confidentiality Service (only authorized access to information,
protection against eavesdropping)
<REQ SR-5>
Provide Security Against Denial-of-Service Service (unimpeded access to data to
avoid denial of service)
<REQ SR-6>
Provide Inter-Domain Security Service (support security requirements across
organizational boundaries)
<REQ SR-7>
Provide Non-repudiation Service (cannot deny that interaction took place)
<REQ SR-8>
Provide Security Assurance Service (determine the level of security
provided by another environment)
<REQ SR-9>
Provide Audit Service (responsible for producing records, which track
security relevant events)
<REQ SR-10>
Provide Identity Mapping Service (capability of transforming an identity which
exists in one identity domain into an identity within another identity domain)
<REQ SR-11>
Provide Credential Conversion Service (provides credential conversion between
one type of credential to another type or form of credential)
<REQ SR-12>
Provide Credential Renewal Service (notify users prior to expiration of their
credentials)
<REQ SR-13>
Provide Security Policy Service (concerned with the management of security
policies)
<REQ SR-14>
Provide Policy Exchange Service (allow service requestors and providers to
exchange dynamically security (among other) policy information to establish a
negotiated security context between them)
<REQ SR-15>
Provide Single Sign-On Service (relieve an entity having successfully completed
the act of authentication once from the need to participate in
re-authentications upon subsequent accesses to managed resources for some
reasonable period of time)
<REQ SR-16>
Provide Trust Establishment Service (the ability to establish trust based upon
identity and other factors)
<REQ SR-17>
Provide Delegation Service (delegation of access rights from requestors to
services, as well as to allow for delegation policies to be specified)
<REQ SR-18>
Provide Credential and Identity Management Service (the ability to manage and
revoke previously established identities/credentials).
<REQ
SR-19>Provide Path Routing and QOS Service (the ability to specify the
communication path and quality of security expected to be provided for a
specific transaction or set of transactions).
<REQ
SR-20>Provide a Quality of Identity Service (the ability to determine the
number of identity/credential mappings that have occurred from the originator
of the transaction to the destination).
<REQ DM-1>
Provide Network Management (management of media, transport, and communication
nodes)
<REQ DM-2>
Provide System Management (management of end devices and applications)
<REQ DM-3>
Support the management of large volumes of data flows
<REQ DM-4>
Support keeping the data up-to-date
<REQ DM-5>
Support keeping data consistent and synchronized across systems and/or databases
<REQ DM-6>
Support timely access to data by multiple different users
<REQ DM-7>
Support frequent changes in types of data exchanged
<REQ DM-8>
Support management of data whose types can vary significantly in different
implementations
<REQ DM-9>
Support specific standardized or de facto object models of data
<REQ DM-10> Support the exchange of
unstructured or special-format data (e.g. text, documents, oscillographic data)
must be supported
<REQ DM-11>
Support transaction integrity (consistency and rollback capability)
<REQ DM-12>
Provide discovery service (discovering available services and their
characteristics)
<REQ DM-13>
Provide services for spontaneously finding and joining a community
<REQ DM-14>
Provide Protocol Mapping Service
<REQ DM-15>
Support the management of data across organizational boundaries.
The domain use
case documents have been imported into Magic Draw UML tool. The tool provides a
central database that maintains the architectural requirements, the key interactions
of the power system functions and the connections among the interactions and
the architectural requirements. Therefore, the domain and architecture experts
can query the database to explore the commonality of the requirements. Using the common requirements, the
architecture experts derived IntelliGrid Architecture common modeling elements.
As mentioned in
Section 1, the major impediment to integration for operational and analytic
purposes can be summarized by:
·
Platform technology heterogeneity
·
Communication technology heterogeneity
·
Data management and exchange technology
heterogeneity
·
Security technology heterogeneity
The proposed solution to this incongruity is
twofold; an integration infrastructure that can be applied to a variety of
technologies combined with a set of Common Modeling Elements. While it is true that adapters will need to
be written potentially for every technology combination, IntelliGrid Architecture Common
Modeling Elements and the dominance and standardization of certain technologies
such as TCP/IP
ensures that the creation of these adapters is relatively simple and not cost
prohibitive. In other words, IntelliGrid Architecture
specifies as many Common Modeling Elements as possible to achieve
interoperability while still allowing technology choices to be made to meet
specific environmental requirements.
The specification of IntelliGrid Architecture Common Modeling
Elements is concrete enough that adapters can be independently supplied off the
shelf by a multitude of application vendors, utilities, consultants or third
party software houses. The Common
Modeling Elements are strict enough so that agreement on a set of technologies
ensures interoperability. In practice
these agreements are called “technology profiles”. Examples include WG 13’s Technology Profiles
documented in their 61970 500 series documents or WG 10’s communication stack
documented in 61850 Part 8-1. In this
way, reuse and supplier competition can help minimize costs and vendor lock in.
In order to create the Common Modeling
Elements, the Team first needed to discover requirements from use cases. The difficulty was that focusing exclusively
on utility use cases provides so much detail that architectural requirements
are somewhat obscured. Instead, the team
sought to abstract away many of the details of the utility use cases so that
what is common and what is different could be more readily exposed. As
described in Section 1, Abstract Use Cases are abstractions derived from Domain
Use Cases. This section analyzes each
Abstract Use Case to determine specific Common Modeling Element requirements.
Analysis
of the Integration of Enterprise Management and Power Systems
Specific to power
systems operations, the team developed the list of abstract enterprise
management services needed to support these operations. This list originally
started from the generic enterprise management functions describe in Section 1
and subsequently refined to meet IntelliGrid Architecture’s requirements. The refinements were
based on the requirement ratings provided in the Domain Template Architectural
Issues (see Vol. 2, Appendix E) for the various domain functions and Abstract
Use Cases. These requirements sometimes do not explicitly raise the need for
enterprise management individual devices. However, the need can be derived.
Examples of these requirements and the derived enterprise management services
are listed below:
1.
For
the Field Device Integration, the requirements of SCADA communicating with
thousands of devices impose the need to perform configuration and fault
management of numerous local and remote devices.
2.
In
Field Device Integration, the requirements for any communications media:
wireline, wireless; raises the need for the enterprise management system to be
able to manage multi-protocol, multi-technology systems and networks.
3.
In
Field Device Integration, the requirements of the fault to be communicated to
sub-station computer within one second, raises the need for tight performance
management and appropriate configuration management.
4.
In
Field Device Integration, the requirements for the communications of IED and
the sub-station master to be 99.999% reliable, implies tight performance and
alarm monitoring, substantial effort in survivable network design and traffic
engineering, and fast fault detection and recovery services.
5.
In
Integrated Security Across Domains, the requirements that the communication
media can have any forms of ownership: utility-owned, jointly owned,
commercially provided, Internet; implies the need for policy management,
establishing and enforcing SLAs, and fairly tight security management.
6.
Integrated
Security and Energy Markets, the requirements for the communications to take
place between various organizations and different administrative domains imply
the need for extensive policy management and enforcements of inter-domain
management policies.
7.
The
functional aspects of all the integration tasks implied similarities with
generic network management functions and the need for integration of these
services for ease of operations and cost reductions.
The OSI architecture model of enterprise management
can be described from the four views of: (i) organizational model, (ii)
Information model, (iii) communication
model, and (iv) functional model. In RM-ODP terms: The OSI Organization Model can be seen as a RM-ODP Engineering Model; The OSI Information Model can be seen as a RM-ODP Information View The OSI communication Model can be seen as a RM-ODP Computational View; And the OSI Functional Model can be seen as a RM-ODP Enterprise Model
With regard to
where components are deployed, both the OSI Enterprise Management Organization Model and
IntelliGrid Architecture Deployment model are flexible enough to allow implementers to deploy
managers, agents, and gateways as needed.
The important point is that both the OSI Enterprise Management Model and IntelliGrid Architecture treat their models orthogonally.
The details of the OSI
Functional (Service) Model are discussed in Section 2.2.1, the OSI Information Model is discussed in 2.3.1, and
the OSI Communication Model is discussed in Section
2.4.1.
Modern energy
market technology like general eCommerce relies on a set of agreed upon
technologies by which components discover each other and interact in a secure
manner. These technologies, typically
provided by an operating system or platform specification such as provided by
W3C or OASIS include, but are not limited to:
·
Reliable messaging
·
Security
·
Partner lookup/discovery
·
Business process information
o
Message formats
o
Message flows
In practice,
energy markets are based on the exchange well known messages. In general, the exact content, format of
these messages has been standardized and thus fixed prior to the initiation of
electronic market activity.
Additionally, a complete business process typically gets codified in the
design of the flow for message exchange as illustrated in Figure 1.
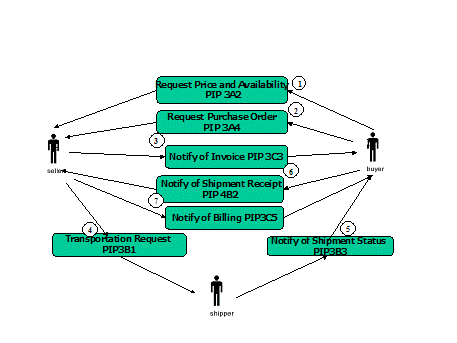
Figure
‑1 Example of eCommerce Message Flow
A message schema
registry is often created to support fixed messaging. Additionally, the registry may allow partners
to discover the script for the flow of message exchange.
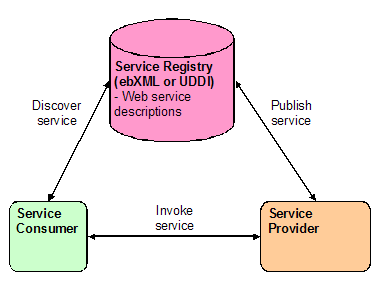
Figure
‑2 eCommerce Registry
However, there are
limitations to a pure fixed messaging based approach including:
·
Business processes are not universal
o
Difficult for vendors to deliver a product that
can work in many markets
o
Difficult to reuse experience
·
Need to integrate across market “seams”
·
Need to integrate with operational systems
·
Need to integrate with legacy market systems
For example,
consider the European wholesale energy trading market. This market consists of
several sub markets each with their own ways of doing business. From a vendor’s point of view, it is
difficult to deliver software that can be readily applied to every European
market because of the lack of commonality.
This in turn drives up the cost of developing solutions. However from a broader perspective, the
purchasing and sale of energy has a large number of commonalities. Ideally, the utility industry would agree on
these commonalities and then allow for market specialization as individual markets
require. The question remains, how can
we find this “lowest common denominator” and how can we enable its use via a
standards based architecture.
A solution to this
problem can be found in the IntelliGrid Architecture – an architecture based on
shared information models, services, and generic interfaces that have been
designed independently of particular business processes.
The IntelliGrid Architecture provides a framework of creating a real time mechanism to which
components connect and discover application-to-application services, data
semantics, and process models. For
Energy Markets, because of the strong requirement for fixed and well known ways
of interacting, this mechanism must be coordinated with the registry. A registry may be managed by some central
authority or distributed to more local interoperability information providers,
but must provide the basis for flexibility.
The important part is that the utility’s Energy Market Transaction
Service can be designed and developed based on the commonalities. When the Energy Market Transaction Service is
deployed in a particular market it needs to be configured to handle the
particulars of a business process. In
this way off the shelf software can be used in a variety of utility Energy
Market markets.
That is, in order
to achieve independence of local market business models, common information
models and generic interfaces must be deployed.
In the case of a Market Transaction Service, the information model must
encompass all data shared between the Transaction Service and Operational
Systems. Additionally, since the content
and the flow of message with business partners are unknown at Transaction
Service design time, the interface to the Transaction Service must be
generic. Common models for Energy
Trading is discussed in Section 2.4.5 and the Generic Interfaces required are
discussed in Section 2.4.6.
An analysis of the
requirements and industry experience for field device connectivity shows the
need to develop a methodology to support interoperability of field devices from
different manufacturers. For the purpose
of this discussion, interoperability is defined as the ability to operate on
the same network or communication path sharing information and commands. There is also a desire to have field device
interchangeability, i.e. the ability to replace a device supplied by one
manufacturer with a device supplied by another manufacturer, without making
changes to the other elements in the system.
Interoperability is a common goal for consumers, equipment vendors and
standardization bodies. In fact, in
recent years several National and International Institutions started activities
to achieve this goal.
The objective of
field device integration is to develop an information exchange methodology that
will meet functional and performance requirements, while supporting future
technological developments. To be truly
beneficial, a consensus must be found between field device manufacturers and
users on the way such devices can freely exchange information.
Approach
The analysis of
the requirements leads to an approach that blends the strengths of three basic
information technology methodologies: Functional Decomposition, Data Flow, and
Information Modeling.
Functional
decomposition can be used to understand the logical relationship between
components of a distributed function, and is presented in terms of abstract
objects representing real field devices that describe the functions,
sub-functions and functional interfaces of those devices.
Data flow is used
to understand the communication interfaces that must support the exchange of
information between distributed functional components and fulfill the
functional performance requirements.
Information
modeling is used to define the abstract syntax and semantics of the information
exchanged, and is presented in terms of data object classes and types,
attributes, abstract object methods (services), and their relationships.
Functions and Objects
The requirements
and resulting analysis point strongly to the use of the concept of object
modeling to represent the devices and their sub-components that one wishes to
communicate with. This means that we identify all of the components (objects)
in the real world that have data, analogue and digital inputs and output,
state, and control points and map these things into generic, logical
representations of the real world devices – a model.
Breaking a real
world device down into objects to produce a model of that object involves
identifying all of the attributes and functionality of each component
object. Each attribute has a name and a
simple or complex type (a class) and represents data in the device that we wish
to read or update. This is a more
flexible approach than numbered, linear, memory mapped, single type point lists
that many engineers are used to dealing with in first generation energy and
process industry system communication systems.
Instead of dealing
with obscure, manufacturer dependent lists of numbered quantities, object
modeling approach lets us define standard names for standard things independent
of the manufacturer of the equipment. If
the equipment has a measurement for which its value is available for reading,
it has the same name regardless of the vendor of that equipment and can be read
by any client program that knows the object model.
In addition to
attributes, other functionality of the device may include things like
historical logs of information, report by exception capabilities, file
transfer, and actions within the device that are initiated by internal or external
command and control inputs. All of these
items imply some type of information exchange between the outside world and the
real world device represented by the object model.
Independence of information
exchange from the application
The analysis of
the requirements leads to the application of an approach that specifies a set
of abstract services and objects that may allow applications to be written in a
manner that is independent from a specific protocol. This abstraction allows both vendors and
equipment owners to maintain application functionality and to optimize this
functionality when appropriate.
An application
model consistent with this philosophy may consist of:
·
Applications written to invoke or respond to the
appropriate set of abstract information exchange service interfaces and
services.
·
This set of abstract services can be used
between applications and “application objects” allowing for compatible exchange
of information among devices that comprise a larger system. However, these
abstract services/objects must be instantiated through the use of concrete
application protocols and communication profiles.
·
The concrete implementation of the device
internal interface to the abstract services can be considered a local issue and
does not necessarily need to be specified explicitly in order to support
interoperability.
·
The local set of abstract services can then be
mapped onto the appropriate set of concrete application protocol and
communication profile services. The result is that state or changes of data
objects are transmitted as concrete data.
Information
exchange models (IEM) can be defined using a top-down approach. An information model in a field device may
support access services as depicted in the following figure.
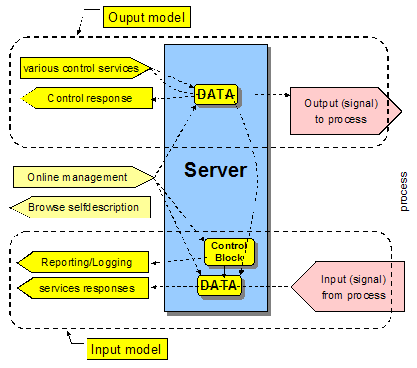
Figure
‑3 Exposing Server Data
The focus of the
server is to provide DATA that make up the field devices information
model. The data attributes contain the values used for the information
exchange. The IEM provides services for:
·
output: control of external operational devices
or internal device functions,
·
input: for monitoring of both process and
processed data, and
·
online management of devices as well as
retrieving the device information model itself (meta-data).
The device
information model data instances contained in the server can be accessed
directly by the services such as Get, Set, Control for immediate action (return
information, set values to data, control device or function).
For many
applications there is a need to autonomously and spontaneously send information
from the server to the client given a server-internal event or to store this
information in the server for later retrieval.
Service model
The abstract
services for an information model can be defined by:
·
a set of rules for the definition of messages so
that receivers can unambiguously under-stand messages sent from a peer,
·
the service request parameters as well as
results and errors that may be returned to the service caller, and
·
an agreed-on action to be executed by the
service (which may or not have an impact on process).
This basic concept
of an IEM is depicted in the following figure
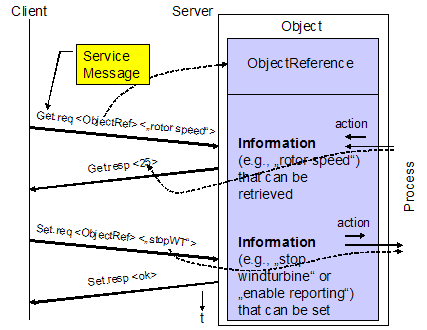
Figure
‑4 Device Information Exchange Model
As described in
Section 1, application integration involves establishing communication between
heterogeneous applications for operational purposes as shown in Figure 5.
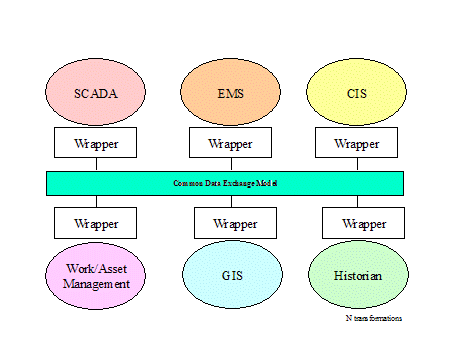
Figure
‑5 Application Integration Example
Recently, the
software industry has realized that application integration can be facilitated
via the exchange of eXtensible Markup Language (XML) messages. Just as
HyperText Markup Language (HTML) has become the universal language of the Web,
businesses have sought a similar language for describing business data. XML has
been adopted by the World-Wide Web Consortium (W3C) and is rapidly becoming the
preferred format for exchanging complex business data internally and between
E-Commerce applications. Similar to HTML, XML allows the designer to create
custom schema and describe how they are used and thus provides the facilities
to create self describing messages. This capability is independent of transport
mechanisms, calling conventions (the order in which parameters are passed or
how data is returned), and data formats. This significantly reduces the size
and complexity of legacy application wrappers. XML- formatted business data
offers standard and extensible information formats, or packages, with which to
exchange information internally and with other businesses.
But utilities
still need a reliable mechanism to send and receive XML packages. To use a post
office analogy, no one waits at the front door for the postman to arrive before
mailing a package. Mailboxes provide a convenient method for storing letters
until a mail truck comes along to pick up the mail and deposit the received
mail. One could use email, but email has not been designed for efficient
automation. Alternatively, message oriented middleware products help link
applications. In general, these software products include a message broker.
With message broker technology, a business application can send business
messages to a broker message queue for later delivery. The messages are then
picked up by the message broker and dispatched to other internal or external
applications. Message brokers facilitate location and technology independence
and have proven to be the best way to link loosely coupled legacy applications
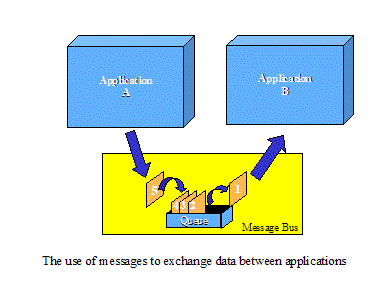
Figure
‑6 Message Queuing
Persistent message
queuing provides the basis for a robust application integration infrastructure
because:
·
Applications are decoupled in time from each
other
·
Provides
fault recovery infrastructure
In addition to
message queuing, a message based integration bus can enhance scalability via
the use of publish and subscribe as shown below:
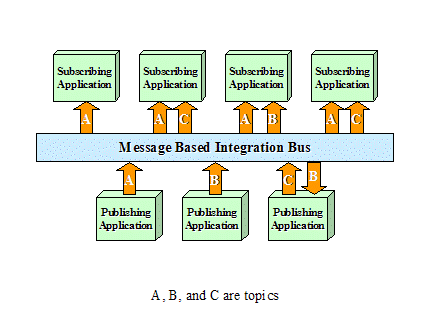
Figure ‑7 Publish and Subscribe
Using
Publish/Subscribe, message sources post messages according to topics. Message consumers receive messages based on
the topics they have subscribed to. As
illustrated in Figure 7, applications publish messages about topics “A”, “B”,
or “C”. Subscribing applications receive
message based on what topic they have subscribed to. Publish/Subscribe decouples applications from
data sources and facilitates scalability because.
·
Publishers do not need knowledge of subscribers
·
Subscribers do not need knowledge of publishers
·
Multiple subscribers can receive information
without publisher configuration.
Furthermore,
publish/subscribe as additional advantages:
·
Publish/Subscribe supports redundancy and
scalability:
·
Multiple publishers can provide the same data
·
More easily scalable for large systems as
publishers only need to publish any given message once.
From the analysis
above, it is clear IntelliGrid Architecture needs to include mechanisms that fully enable
publish/subscribe technology for utilities.
Specifically, this means specializing publish/subscribe to take full
advantage of IntelliGrid Architecture Common Modeling Elements. As will be discussed in later sections, this
specifically means that publishers should publish messages that comply with a
common information model and subscribers should be able to browse the common
information and subscribe to elements in it.
As described
previously, technology profiles are used to ensure interoperability of
components adhering to a standard technology independent architecture. However, technology profiles in themselves do
no guarantee interoperability. The most
significant remaining problem consists of conflicting data semantics. Technology profiles only provide tools
for inter-application communication and do not facilitate the creation and
management of common data semantics.
“Data Semantics” means an understanding of the procedures, message
formats and conditions under which data is exchanged. Without a proper definition of common
semantics, using profiles alone can simply create a more sophisticated set of
point-to-point links, i.e. more “islands of integration”, rather than a real
architecture.
To address these
challenges, one needs to not only create a communication infrastructure to
automate the exchange of data, but also to establish common data
semantics. In this way data in existing
systems can be can become shared knowledge.
The understanding
of data semantics requires a unified data model. The coalescing of an enterprise’s many data
models into a more rational set whose purpose is to enable analysis is often
called data integration. Data integration is somewhat different from most
programming tasks in that the goal is not necessarily to add new features, but
rather to link and expose existing data while minimizing programming. Traditionally, asset management analysis has
relied on deployment of an asset management data warehouse for the creation of
a unified view. The data warehouse can
become:
·
The “system of record” for all assets owned by
the company.
·
The “system of record” for all compliance data.
·
Provides a single point of access for cost,
revenue, and operational data on all assets for planning purposes.
·
Supplies an asset risk management platform.
In turn,
establishing common data semantics requires a unified data model. The coalescing of an enterprise’s many data
models into a smaller more rational set whose purpose is to enable
decision-making is often called data integration. Data integration is somewhat
different from most programming tasks in that the goal is not necessarily to
add new features, but rather to link and expose existing data while minimizing
reprogramming. The creation of a common
architecture is inextricably linked to the creation of shared data models.
Once a unified
data model and technology profiles are in place, software applications can be
written independently of the underlying technology. Even if a vendor produces a product
conforming to a technology profile not used by a utility, the product can be
used off the shelf if the utility has the correct profile conversion adapter
that may also be purchased off the shelf.
For example, a Java based common modeling element compliant application
can be plugged into a Web Services based common modeling element compliant
integration deployment if the utility has a Java to Web Services adapter. In this particular case, this adapter would
be available from multiple vendors.
In order for a
data model to be used by multiple applications, its semantics must be
understood and managed. The commonly
accepted way to manage data semantics is by describing what, where, and how
data is used in a metadata management service.
Metadata is “data about data”. A metadata management service serves as a
central point of control for data semantics, providing a single place of record
about information assets across the enterprise. It documents:
·
Where the data is located
·
Who created and maintains the data
·
What application processes it drives
·
What relationship it has with other data
·
How it should be translated and
transformed.
This provides
users with the ability to utilize data that was previously inaccessible or
incomprehensible. A metadata management
service also facilitates the creation and maintenance of a unified data model.
Lastly, a common service for the control of metadata ensures consistency and
accuracy of information, providing users with repeatable, reliable results and
organizations with a competitive advantage.
In summary, data
management and exchange integration using IntelliGrid Architecture involves looking at the big
picture, using the following concepts:
·
Common
data semantics, defined as a set of abstract services
·
A
unified information model
·
A
metadata management service to capture the data about the data
However, a
particular integration project may encompass data from a large or small set of
applications. One does not need to
undertake a major project that requires many months to complete. The issue here is the development of a
long-term enterprise wide integration strategy so that a small integration
project does not become just another slightly larger island of automation. Thinking at the enterprise level while
integrating at the department level minimizes risk and maximizes the chances
for long-term success. Part of this
enterprise view is the understanding of enterprise data semantics and the
business decision-making process.
TC57 WG 13's 61970
Part 403 Generic Data Access (GDA) provides an example of a Distributed Data
Management Service. GDA provides a generic request/reply oriented interface
that supports browsing and querying randomly associated structured data –
including schema (class) and instance information.
Traditional Data Warehousing
Solutions
Data integration
has in the past been executed with point-to-point solutions. A Common Model Element based approach is
better over point-to-point because it scales much more economically. A common Data Management service bestows the
following benefits: Cost reduction by lessening the number of system interfaces
you need to build and administer, better use of resources through reduced
employee training and code reuse, system flexibility for faster accommodation
of business changes, and enterprise visibility – essential to reducing risk
exposure from market uncertainty.
Asset analysis
almost invariably involves integration of systems that were never intended to
be integrated. Asset analysis frequently
gathers data from many sources including:
·
Asset Management System (AMS)
·
Work Management System (WMS)
·
Outage Management System (OMS)
·
Geographic Information Systems (GIS)
·
Energy Management System (EMS)
·
Distribution Management System (DMS)
·
Customer Information System (CIS)
·
Measurement Archive
Integration of
data from these systems can be difficult.
Each system may have its own way of modeling power system assets and
interfaces to each of these systems may be radically different. Fundamentally, asset analysis involves
looking at the big picture. However,
integration may at first only need encompass data from a small set of
applications. One does not need to
undertake a major project that requires many months to complete. The goal should be the development of a
long-term enterprise wide strategy so that a small project does not become just
another slightly larger isolated island of integration. Thinking at the enterprise level while
integrating at the department level, minimizes risk and maximizes the chances
for long-term success. Part of the
challenge of implementing this enterprise view is understanding asset related
data semantics and decision-making processes.
What is a data warehouse
A data warehouse
has typically been implemented as a database where data from operational
systems is copied for the purpose of analysis.
Often the data warehouse is used to consolidate data that is spread out
across many different operating divisions as a way to efficiently access data
and make it available to a wide selection of users.
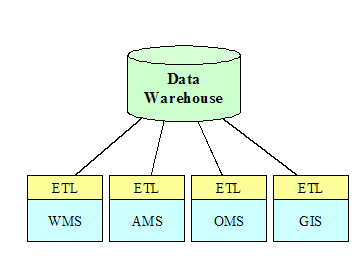
Figure
‑8 Traditional Data Warehouse Architecture
In order to copy
the data to the warehouse, specialized wrappers are created to Extract,
Transform, and Load (ETL) the data. In
fact, this step is often the most expensive and time-consuming part of
warehouse construction.
The diagram above shows how operational needs
(that is tactical as opposed to strategic goals) can be met using a standard
common information model. In this case,
real-time cooperation of applications allows business processes to be
automated. However, the object classes
represented in a common information model are abstract in nature and may be
used in a wide variety of scenarios. The use of a common information model goes
far beyond its use for application integration.
The issues associated with construction of a data warehouse are very
similar to application integration. That
is, one needs to unify information from a variety of sources so that analysis
applications can produce meaningful and repeatable results. This standard
should be understood as a tool to enable integration in any domain where a
common power system model is needed to facilitate interoperability of data. The
diagram below illustrates how a common information model can be used as the
model for a data warehouse.
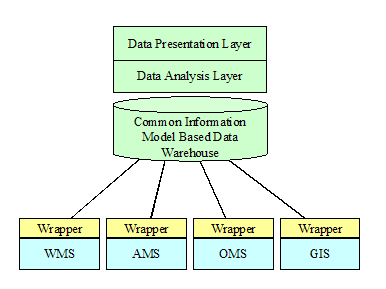
Figure
‑9 Common Information Model Based Data Warehouse
The diagram above illustrates a data
warehouse that aggregates data from a collection of applications. The data is then analyzed and presented to
the user for the purpose of making strategic decisions. A standard common information model provides
an ideal starting point when designing the schema of the data warehouse because
analysis requires a single comprehensive and self-consistent model. In this case, the wrappers extract,
transform, and load application data into the data warehouse. It should be noted however, that almost all
wrappers developed to date as part of a warehouse project are developed
independently from the wrappers used for application integration. The reason this inefficiency was allowed to
occur is that application integration projects have historically involved
different stakeholders and software vendors.
Furthermore, no vendor independent standards have existed for wrapper
development. However, now at last,
standards have been developed designed to allow a single wrapper to be used for
both purposes.
As described
above, plug and play also requires a common technical mechanism by which
applications connect and expose information.
In fact, it is agreement on common technical mechanisms that fully
enables the creation of a single set of wrappers for application integration as
well as data warehousing. More
generally, a data warehouse provides a technology specific mechanism for
creating an architected information management solution to enable analytical
and informational processing despite platform, application, organizational, and
other barriers. In fact, the data
warehouse hides from the requester all the complexities associated with diverse
data locations, semantics, formats, and access methods. The key concepts of this more technology
neutral description is that barriers are being broken and information is being
managed and distributed, although no preconceived notion exists for how this
happens.
Star schema
Data warehouses
are about making better decisions. In
general the warehouse is subject-oriented (focused on a providing support for a
specific set of analysis applications), time-variant (has historical data), and
read-only (the warehouse is only typically used for analysis and not for
centralized control of the operation systems).
Data warehouses
are typically organized using a “star” configuration. This simply means that there is a central
“fact” table and related “dimensions”.
The most significant characteristic of a star configuration is its
simplicity. Given the very large size of
many data warehouses, this simplicity increases query performance because only
a few tables must be joined to answer any question. The diagram below illustrates an outage
reporting data warehouse with a four dimension star configuration:
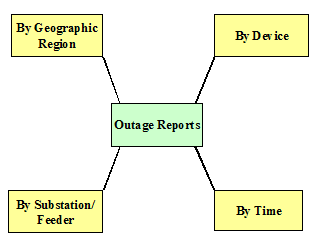
Figure
‑10 Example Of A Data Warehouse Star Schema
In this example,
the data warehouse is used to provide support for outage analysis. It may get
data from EMS, AMS, Measurement Archive, and GIS applications. Because of the enormous amount of data that
they must manage, data warehouses are always optimized for a limited set of
applications and, therefore, they may not be particularly useful in supporting
unanticipated analysis applications.
While more fact tables and dimensions may be added, it is not practical
to optimize the warehouse for all possible uses. As the database schema varies from a simple
star configuration:
·
Performance can significantly decrease since
multiple tables must be joined; and
·
Queries get complicated. A star configuration is easy to
understand. As we complicate the schema,
we decrease the intuitiveness of the warehouse.
Applications of data warehouses
·
Querying and reporting - Basic querying and
reporting is most representative of traditional uses of data warehouses for
analytical purposes. The data is
retrieved in accordance with either regular standard reports or in response to
a particular question. It is then
formatted and presented to the user either on screen or in a print out.
·
Online Analytical Processing (OLAP) - OLAP
introduces analytic processes and a degree of variability into the user
interaction. The first steps of OLAP are
similar to querying and reporting. After that, the user can manipulate the data
and view new results in different ways.
For example, the user may want to see a monthly total trended over a
two-year period.
·
Data mining - Data mining is an umbrella term
for a series of advanced statistical techniques. Data mining seeks to be predictive – searching
through large volumes of data looking for patterns in an effort to determine
what may happen based on probability. Data mining is also discovery oriented –
it allows the user to discover correlations without the user necessarily asking
for them explicitly.
·
Portal - A portal provides a user-friendly
interface for aggregated and summarized data as well as views created by
reports, OLAP, and data mining tools. Portals typically rely on a web-based
view that can be customized for individual users.
Challenges of Traditional Warehouse
Based Solutions
Experience has
shown that in many cases data warehouses can fail to meet users’ needs. A major problem is the sheer size of many
data warehouse projects. The attendant
challenges of trying to track and supervise something as gargantuan as the
consolidation of a collection of heterogeneous and complex systems can be
enormous. According to industry surveys,
fully half of the centralized data warehousing projects implemented using
traditional methods fail within their first year and less than one in twenty
ever reach their envisioned conclusion. This
section focuses on the challenges of centralized data warehouses and how they
can affect the project.
Up to date data
Traditionally data
warehouses have relied on ETL performed as a batch process. This was the preferred mechanism, because ETL
could be performed at night when the user load on the data warehouse and
operation systems are light. The
difficultly with the traditional approach is that data in the warehouse is not
up to date enough to make operational related decisions. For example, when using batch oriented ETL,
analysis applications are unable to support users who make inquiries about
today’s activity. More recently,
utilities have frequently utilized an architecture that leverages the
installation of an Enterprise Application Integration (EAI) tool. These tools facilitate application
integration via the real-time exchange of inter application messaging on a
message bus.
Using a message
bus facilitates the installation of data warehouses. Message bus designers typically make at least
some attempt to normalize the data from the operational systems towards some
kind of shared data model. The diagram
below illustrates this architecture.

Figure
‑11 Data Warehouse Connected to a Message Bus
Unstructured data
Asset management
analysis can aggregate information from many sources. For example, an analysis application may examine:
·
Inspection routines
·
Maintenance procedures
·
Engineering diagrams
·
Regulations
·
Web Pages
The difficulty in
aggregating this data is that it may not be stored in a database, but rather
contained in a set of documents.
Ideally, the goal would be to join unstructured content, including
documents, emails, pictures, and so on with data in databases. However, unstructured content is almost
always excluded from current data warehouses because of difficulties in accessing
it, joining it with structured data, and storing it in the data warehouse. Furthermore, such content can be volatile and
is almost always voluminous. Determining
when the data has changed and when to load a new version may be difficult. Entirely separate systems, typically called
Knowledge Management or Content Management systems, have evolved independently
of data warehouses because of the difficulty in merging these worlds. Copying all unstructured data into a data
warehouse is typically not a practical option.
A unified data model
In the absence of
standards, the creation of a single asset data model can be a very large amount
of work. To create a unified model, the
warehouse designer must thoroughly understand all applications and databases to
be integrated. After that, the designer
must rationalize all the existing data models into a single data model. It is often so difficult to create a single
unified model that data warehouse implementers frequently rely on some
pre-existing proprietary design.
However, even customizing a pre existing data model is non-trivial. One needs to consider the combined
information needs of all users who may access the warehouse for decision
support, whether they are in planning, marketing, maintenance, operations, or
senior management. As it is impossible
to optimize for all users, it is inevitable that the design utilizes a “least
common denominator” approach with regard to its focus on any one goal.
Compromises may become so drastic that the resulting product is universally
criticized.
To meet the goals
of subsets of users, the data may be copied again out to a smaller data mart
whose sole function is to support a more narrowly defined analysis application
as shown below. Defining data marts as a
separate layer makes it possible to optimize them for a variety of specific
user needs. The key characteristic of
this data warehouse architecture is that data is copied, transformed into a
different relational schema, and then stored multiple times in order to meet
usability and performance goals.

Figure
‑12 Data Mart Proliferation
As the number of
copies of data increases, so too does the cost of storing those copies and
maintaining their consistency. As the
volume of real-time data stored in the warehouse grows, queries tend to run
slower while the percentage of data that are actually used decreases
proportionally. While the addition of a
message bus helps bring the data warehouse more into real-time, it leaves the
fundamental issues related to copying all the data in to a warehouse with a
fixed configuration unsolved. The fact
that the data warehouse tends to be optimized only to the particular set of
applications that were foreseen during warehouse design remains a problem.
Further
exacerbating this problem is that utilities are no longer static business
entities. Competition due to
deregulation and changing regulatory requirements means that utilities must
respond more quickly to changing business conditions. Asset analysis users will demand new
information, changes to existing reports, and new kinds of reports as
well. The data warehouse must keep pace
with the business, or even stay a step ahead, to remain useful. Especially if
the data warehouse is used to help determine the future impact of changes to
the business environment.
Maintenance difficulties
In addition to the
challenges mentioned above, purely technical issues related to ongoing
maintenance can also limit the usefulness of a data warehouse. The physical size of the warehouse can
complicate this routine effort. A
warehouse of any size must be re-indexed and repartitioned on a regular basis,
all of which takes time. The size of the
database also affects the backups and preparations for disaster recovery, both
of which are critical if the company intends to protect its investment in the
warehouse.
Applications use
the standard interfaces to connect to each other directly or to an integration
framework such as a message bus. Generic
interfaces allow applications to be written independently of the capabilities
of the underlying infrastructure.

Figure
‑13 Example Of A CIM/GID Based Data Warehouse
The Generic Interface needs to
include the ability to notify clients when data has been updated in the server.
This functionality provides an important piece of the puzzle when constructing
an infrastructure that enables a single point of update for model changes. For
example, changes in an EMS modeling server can be used to drive the configuration of an
archive or implement a synchronization routine with an asset management system
as shown below.

Figure
‑14 Example of CIM/GID Warehouse Connected to a Message Bus
The IntelliGrid Architecture
interfaces are generic and are independent of any application category. The advantage of using generic interfaces
instead of application-specific ones include:
·
Facilitates
the use of off-the-shelf integration technology – The interfaces have been
designed to be implemented over commercially available message bus and database
technology.
·
Creates a consistent and easy to use integration
framework by providing a unified programming model for application integration.
Enhances
interoperability by “going the last mile”. Agreement on the “what” of data is
not enough to ensure component interoperability. We also need to standardize on
“how” data is accessed. To provide a simple analogy, we standardize on a
110/220 volt 60 hertz sine wave for residential electrical systems in the
US. This is a standardization of
“what”. However, we also standardize the
design of the plugs and receptacles.
This is a standardization of the “how”. The standardization of plugs and
receptacles means that we don’t need to call an electrician every time we want
to install a toaster. Similarly with software, standardizing on the interface
means a connector does not need to be created from scratch every time we install
a new application.
Since application
vendors can “shrink wrap” a Common Modeling Element compliant wrapper, the use
of these constructs can lower the cost of integration to utilities
by fostering the market for off-the-shelf
connectors supplied by application vendors or 3rd
parties. The time and money associated with data warehousing/application
integration wrapper development and maintenance is high. Typically, most money
spent on integration is spent on the wrappers. An off-the-shelf Common Modeling
Element compliant wrapper can replace the custom-built “Extraction and
Transformation” steps of an ETL process. The availability of off-the-shelf this
type of standard compliant wrappers is a key to lowering data warehouse
construction costs very significantly.
It is important
that the Generic Interfaces support viewing of legacy application data within
the context of a shared model. The
Generic Interfaces take full advantage of the fact that the
Common Information Model is more than just a collection of related attributes –
it is a unified data model. Viewing data in a Common Model context helps
eliminate manual configuration and provides a means for a power system engineer
to understand how enterprise data is organized and accessed. The
interfaces allow legacy data to be exposed within the context of this unified
model. This makes data more understandable and “empowers the desktop” by
enabling power system engineers to accomplish many common configuration tasks
instead of having to rely on IT personnel.
Table 1 shows that the Policy security function is a function
that is required in ALL aspects of the security process. Additionally, the table also shows that an
appropriate Security Management Infrastructure needs to be deployed in order to
monitor and perform re-assessment of the security system within a Security
Domain.
|
Table
‑1:
Relating Security Processes to Functions and Services
|
|
General Security Process Name
|
Security Function Name
|
|
Assessment
|
Policy
SMI
|
|
Deployment
|
Trust
Access Control
Confidentiality
Integrity
Policy
SMI
|
|
Monitoring
|
SMI
Policy
|
|
Policy
|
Policy
|
|
Training
|
Policy
Training
|
In order to
actually implement the security functions, within a Security Domain, several
security services have been identified. Table 2 shows the relationships of the Functions to the
Security Services that would be used to actually implement the security
function.
|
Table
‑2:
Relating Security Processes to Functions and Services
|
|
Function Name
|
Service Name
|
|
Access Control
|
Authorization for Access Control
- All Trust related Services
|
|
Confidentiality
|
Confidentiality
Path Routing and QOS
Firewall Transversal
|
|
Integrity
|
Information Integrity
Profile
Protocol Mapping
|
|
Policy
|
Policy
|
|
Security Management Infrastructure (SMI)
|
Audit
User and Group Mgmt.
Security Assurance
Non-Repudiation
Security Assurance
Policy
-- Management of all services
|
|
Trust
|
Identity Establishment
Identity Mapping
Quality of Identity
Credential Conversion
Credential Renewal
Delegation
Privacy
Single Sign-on
Trust Establishment
|
Further, it is
notable that there are inter-relationships between the services themselves. As
an example, Table 3 indicates that in order to provide the Identity
Mapping Service the Credential Conversion service is needed.
|
Table
‑3:
Primary Services and the additional Security Services required to implement
|
|
Service
|
Required Services
|
|
Audit
|
Policy
Security Assurance
|
|
Authorization for Access Control
|
Identity Establishment
Information Integrity
Setting and Verifying User
Trust Establishment
Non-Repudiation
Quality of Identity
|
|
Confidentiality
|
Identity Establishment
Authorization for Access Control.
Privacy
Trust Establishment
Path Routing and QOS
|
|
Delegation
|
Identity Mapping
|
|
Identity Establishment
|
Credential Renewal
Information Integrity
Policy
User and Group Mgmt
Audit
Policy
|
|
Identity Mapping
|
Identity Establishment
Credential Conversion
Non-Repudiation
Quality of Identity
|
|
Information Integrity
|
|
|
Inter-Domain Security
|
Identity Mapping
Security Protocol Mapping
Security Against Denial of Service
Trust Establishment
Security Service Availability
Path Routing and QOS
|
|
Non-Repudiation
|
Audit
Security Assurance
|
|
Policy
|
|
|
Profile
|
Audit
Identity Mapping
|
The combination of
Table 1 through Table
3 should allow users to determine what security
services need to be implemented in order to achieve a specific Security
Process. However, there are different
services required for inter-domain and intra-domain exchanges. These services
are shown in Table 4.
|
Table
‑4:
Services needed for Intra/Inter Domain Security
|
|
Security Service
|
Intra-Domain
|
Inter-Domain
|
Comments
|
|
Audit
|
m
|
m
|
|
|
Authorization for Access Control
|
m
|
m
|
|
|
Confidentiality
|
o
|
m
|
|
|
Credential Conversion
|
o
|
m
|
|
|
Credential Renewal
|
m
|
m
|
|
|
Delegation
|
o
|
m
|
|
|
Firewall Transversal
|
o
|
m
|
|
|
Identity Establishment
|
m
|
m
|
|
|
Identity Mapping
|
o
|
m
|
|
|
Information Integrity
|
m
|
m
|
|
|
Inter-Domain Security
|
Not Applicable
|
m
|
|
|
Non-Repudiation
|
m
|
m
|
|
|
Path Routing and QOS
|
o
|
o
|
|
|
Policy
|
m
|
m
|
|
|
Privacy
|
o
|
o
|
|
|
Profile
|
m
|
m
|
|
|
Quality of Identity
|
See comment
|
m
|
In order to provide this service for inter-domain,
it must be available for intra-domain applications to make use of.
|
|
Security Against Denial of Service
|
o
|
m
|
|
|
Security Assurance
|
m
|
m
|
|
|
Security Protocol Mapping
|
o
|
m
|
|
|
Security Service Availability Discovery
|
m
|
m
|
|
|
Setting and Verifying User Authorization
|
m
|
m
|
|
|
Single Sign-On
|
m
|
Not Applicable
|
|
|
Trust Establishment
|
m
|
m
|
|
|
User and Group Management
|
m
|
m
|
|
|
