|
The mechanism used
to exchange data is determined by an application’s interface. However, the native interface provided by an
application is typically limited. For
example, often legacy interfaces do not provide a means to discover what data
is processed by a particular component at run time other than a rudimentary
listing of legacy IDs. Furthermore, legacy data cannot typically be viewed
within the context of an inter-application data model such as a view of a power
system network model
Typically legacy
interfaces:
·
Do not expose data within the context of a
common inter-application data model.
·
Do not provide a means to discover what business
object instances are serviced by a particular component instance other than a
rudimentary listing of legacy IDs (tags) that cannot be viewed within the
context of an inter-application data model such as a power system network
model.
Without a means to
discover what data an application processes, plug and play is nearly impossible
to achieve. To address these impediments
to plug and play and the need for a common exchange mechanism, or “how” data is
exchanged is needed. The phrase “Generic
Interface” is an umbrella term for four interfaces types:
·
An interface for mapping names to ID’s and visa
versa.
·
A request/reply oriented interface that supports
browsing and querying randomly associated structured data – including schema
(class) and instance information.
·
A publish/subscribe oriented interface that
supports hierarchical browsing of schema and instance information. This interface would typically be used as an API for publishing/subscribing to XML formatted
messages.
Applications use
the standard interfaces to connect to each other directly or to an integration
framework such as a message bus or data warehouse. A technology neutral
interface allows applications to be designed independently of the capabilities
of the underlying infrastructure.
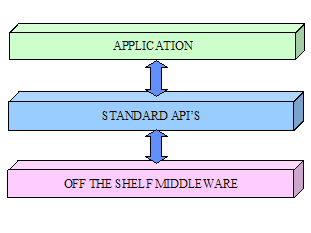
Figure
‑17 Applications Connect to Off the Shelf
Middleware Via the Standard API’s
Legacy application
interfaces most often are accessed using a variety of interface technologies
including:
·
RPC/API based (CORBA, COM, Java, C language)
·
File based
·
W3C Web Services/XML/HTTP based
·
RDBMS/SQL based
A technology
neutral generic interface is typically specified using UML. UML is deployment platform neutral. The Generic Interface can be realized using a
variety of middleware technologies including:
·
RPC/API based CORBA, COM, Java, or C language
specializations
·
W3C Web Services/XML/HTTP based
The IntelliGrid Architecture project
is focused on deriving common services that facilitate the integration of
systems in spite of the above-mentioned discontinuities. To overcome platform heterogeneity, the
common information model and technology independent interface are used. To overcome semantic heterogeneity a common
information model is used. To overcome
data access mechanism heterogeneity a general purpose Generic Interface is
used. The Generic Interface provides
access to a common information model. A
common information model is used as the common language that all services use
to communicate. While the different
implementations of the common services that expose the generic interface are
not necessarily interoperable, “off the shelf”, the mapping from one technology
specific implementation to another can be standardized and relatively straight
forward. The diagram below illustrates
these concepts:
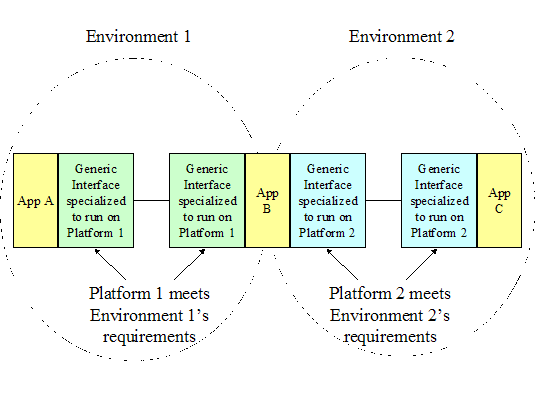
Figure
18
Applying Technologies to Environments
In Figure 18, Application A, B, and C all communicate using the
common information models and generic interfaces, but how the common modeling
elements are implemented depends on the environment
This section
describes how the requirements of the different environments leads to a set of
common services and how the functionality associated with each service can be
accomplished via the use of the technology independent interfaces. That is, the functionality associated with
each service can be accessed via the manipulation of its portion of a common
information model exposed at its interface.
Later sections show how specific technologies can be mapped to the
technology independent interfaces to meet the specific requirements of an
environment.
Thus, the standard
interface can be deployed as an API
or as a wire level protocol such as Web Service based messaging. The interface
is generic because it can be use to access any application. This technology independent generic interface
is then mapped to specific technologies to accomplish a given service function
within the context of an environment’s requirements. The diagram below includes several scenarios
depicting how a generic interface might be used:
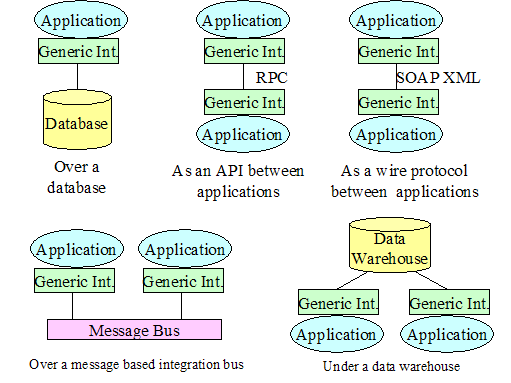
Figure
19 Ways
That A Generic Interface Can Be Applied
Regardless if
these interfaces are implemented as an API or on the wire, a generic interface should
provide the following key functionality required for creation of a plug and
play infrastructure:
·
Interfaces are generic and are independent of
any application category and integration technology. This facilitates
reusability of applications supporting these interfaces.
·
Interfaces support schema announcement/discovery
– The schemas are discoverable so that component configuration can be done
programmatically at run time. Programmatically exposing the schema of
application data eliminates a great deal of manual configuration.
·
Interfaces support business object namespace
presentation – Each component describes the business object instances that it
supports within the context of a common namespace shared among all applications
such as a power system network model like the EPRI Common Information Model
(CIM). It is not enough to merely expose the application data schema, one must
also expose what specific breakers, transformers, etc., that an application
operates on. This also eliminates manual
configuration as well as provides a means for a power system engineer to
understand how enterprise data is organized and accessed.
The advantage of
using generic interfaces instead of application-specific ones cannot be over
emphasized. The benefits of using
generic interfaces include:
·
The interfaces developed are middleware neutral
and were designed to be implemented over commercially available message bus and
database technology. This means a single
wrapper can be used regardless on the technology used to perform integration.
·
As
application category independent, the same interfaces are used to wrap any
application. This means that new
wrappers do not need to be developed every time an application is added to the
system.
·
Creates a consistent and easy to use integration
framework by providing a unified programming model for application integration.
·
Enhances
interoperability by “going the last mile”. Agreement on the “what” of data is
not enough to ensure component interoperability. We also need to standardize on
“how” data is accessed. To provide a simple analogy, we standardize on a 110/220
volt 60 hertz sine wave for residential electrical systems in the US. This is a
standardization of “what”. However, we also standardize the design of the plugs
and receptacles. This is a standardization of the “how”. The standardization of
plugs and receptacles means that we don’t need to call an electrician every
time we want to install a toaster. Similarly with software, standardizing on
the interface means a connector does not need to be created from scratch every
time we install a new application.
·
Since application vendors can “shrink wrap” a
wrapper based on a standard information model and interface, the use of an
information model and generic interface can lower the cost of integration to
utilities by fostering the market for off-the-shelf
connectors supplied by application vendors or 3rd
parties. The time and money associated with data warehousing/application
integration wrapper development and maintenance is high. Typically, most money
spent on integration is spent on the wrappers. An off-the-shelf standard
information model/generic interface wrapper can replace the custom-built
“Extraction and Transformation” steps of an Extraction/Transformation/Load
warehouse process. The availability of off-the-shelf standard information
model/generic interface compliant wrappers is a key to lowering application
integration and data warehouse deployment and maintenance costs very
significantly.
Generic Interfaces
support viewing of legacy application data within the context of a shared
model. The generic interfaces take full advantage of the fact that an
information model is more than just a collection of related
attributes – it is a unified data model. Viewing data in a shared model
context helps eliminates manual configuration and provides a means for a power
system engineer to understand how enterprise data is organized and accessed. The
generic interfaces allow legacy data to be exposed within a power system
oriented context. This makes data more understandable and “empowers the
desktop” by enabling power system engineers to accomplish many common
configuration tasks instead of having to rely on IT personnel.
In order to fully
enable a common information model, a generic interface needs to specify two
related mechanisms. The first specifies a programmatic interface that a
component or component wrapper must implement. The second specifies how an
information model is exposed via the programmatic interface. The later concept
is embodied in the term “namespace”. A
namespace not only includes type information, but also typically includes
instance information as shown below:
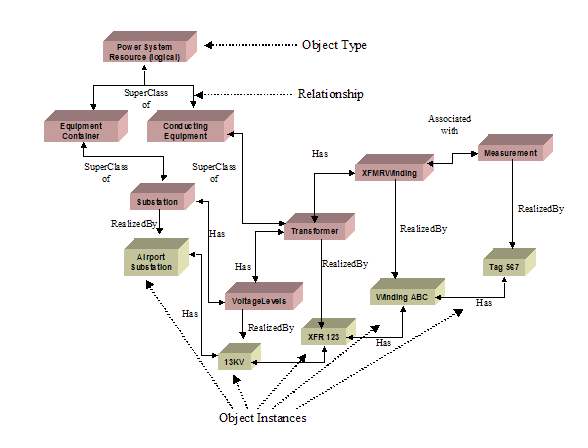
Figure
‑20 Example Namespace
IntelliGrid Architecture includes a
strawman Generic Interface model. The
intent of including this model is not to specify a standard for
interoperability, but to more precisely describe what IntelliGrid Architecture architects
believe a generic interface should look like.
The IntelliGrid Architecture Generic
Interface Strawman is used to manipulate data at an integration layer. The IntelliGrid Architecture strawman interface is not a
replacement for any existing interface; rather it is used to facilitate
integration of previously nonintegrated systems. For example the Generic Interface would be
used to integrate:
·
Utility specific data management
·
Network/system management
·
Security
·
Platform services
Analysis of the
requirements leads to the conclusion that the Generic Interface should include
the following functionality:
·
Create/DeleteNamespaceNode
·
GetNamespaceNodeID/GetNamespaceNodeName
·
Read/QueryNamespace
·
UpdateNamespace
·
Start/StopStream
·
Subscribe/Notify
These methods
allow a client to act on an information model presented in a server’s namespace
and meet all of the required capabilities.
The diagram below presents a UML diagram of IntelliGrid Architecture Generic Interface
Strawman:
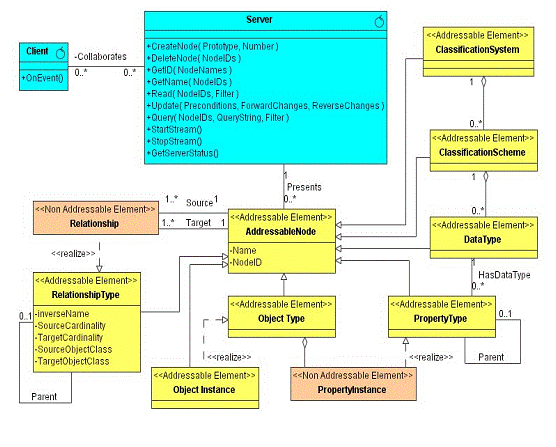
Figure
‑21 Example Generic Interface
Figure 21 contains a UML diagram for a strawman generic
interface. In this case, how a client
collaborates with a server is described in the two interface classes called
Client and Server. The client implements
a single method called OnEvent that allows the server to asynchronously notify
the client. The server implements 10
methods. The first two methods
(CreateNode and DeleteNode) allow a client to create or delete a node from the
server’s namespace. This node could be
metadata such as a new breaker type or new instance data such as a specific new
breaker installed in a substation.
The
second two methods (GetID and GetName) allow a client to discover the various
names for a namespace node. The ID
provides a key to map the names together.
Different names for node typically exist depending on the application
and user. For example, planning may call
a bus one name and the EMS may call the same bus something else. The important thing is that we can manage
names for metadata and instance data in a consistent way.
The
next three methods (Read, Update, Query) allow a client to read, write or query
for node information. For instance these
methods would allow a client to read or write information about a new breaker
type of a new breaker instance installed in a substation.
The
last two methods (StartStream and StopStream) allow a client to down load files
to the server. These files can be used
to update software in the server as well as transfer data files such as
oscillographic data.
The
last method (GetServerStatus) allows a client to discover application layer
status information about the server. For
instance, a client might discover the amount of memory left for events in a
protective relay.
Below
the interface classes, the class AddressableNode defined the properties every
node in a namespace has – a default name and an ID. Several different types of namespace nodes
exist – nodes that represent object types and object instances, as well as
property types and relationship types.
These are all addressable; meaning they have their own unique identifies. Some information in an address space cannot
be accessed unless it is by its parent.
This type of information is contained in non-addressable nodes. For example, the status (a property instance)
of a breaker is only accessible via the breaker instance. It does not make sense to have a status
without knowing what the status is about.
Similarly relationships only exist between nodes.
The
last three namespace related classes provide the ability to create type
systems. For exampled, XML Schema, ASN.1 or DNP3 all define a type systems. Having this information available in the
namespace allows different ontologies such as a populated DNP3 namespace be
related to another such as a populated CIM model.
In
summary, this strawman interface is technology neutral but specifies enough
information to ensure interoperability when combined with technology
profiles. The goal of presenting this
strawman is not to attempt to influence any particular standard or
interface. Rather it is only intended to
show what technology independent might look like for educational purposes.
|
