|
This section provides a discussion of several
current technologies that exemplify how the IntelliGrid Architecture can be
realized. This section does not attempt
to discuss all technologies that may be used to create a unified architecture
for integration and analysis. Rather, it
only includes a discussion of a small set of technologies that demonstrate
IntelliGrid Architecture architectural issues and goals.
The complete set of recommended IntelliGrid Architecture data exchange and management
technologies are described in detail in the Appendix D of this volume.
As stated in Section 1, IntelliGrid Architecture is focused on
an architecture for integration and analysis.
This means that in general, IntelliGrid Architecture analysis treats systems as black boxes. IntelliGrid Architecture is more concerned with linking
applications as opposed to how they work internally. This significantly reduces the technologies
IntelliGrid Architecture team examines – especially with regard to data management and
exchange technologies.
A prime of example of the level of
abstraction that the IntelliGrid Architecture deals with is provided by data storage
and back up. While one would certainly
argue that reliable storage and back up of data is a key attribute of good
system design, these topics are largely out of scope of IntelliGrid Architecture because how an
application stores and backs up its data can be seen as a problem within the
application black box. Since IntelliGrid Architecture is an
integration and analysis architecture project and not a technology/development
design project, data storage and backup are out of scope.
Previous sections have explained the need for
information discovery. To discover the
structure of data, systems must agree on how data is encoded. Recently the eXtensible Markup Language (XML)
has emerged as the universal means to encode self-describing data. XML is supported by a wide variety of vendors
and has achieved a high degree of acceptance in the market place.
Information discovery also means that you can
discover meaning of data in systems.
That is, central to the notion of the unification and aggregation of
information is the notion of ontology – a term borrowed from philosophy
that refers to the science of describing entities and how they are
related. Ontology is important to
information integration since it provides a shared, common understanding of
data. By leveraging this concept we can:
·
Organize and share the entirety of asset related
information.
·
Manage content and knowledge in an
application-independent way
·
Facilitate the integration of heterogeneous data
models for the purpose of data warehousing.
Essentially, ontology is a conceptual
information model. An ontology describes
things in a problem domain, including properties, concepts, and rules, and how
they relate to one another. Ontology
allows a utility to formalize information semantics (the meaning of data)
between information systems.
The
World Wide Web and ontology
Ontology also helps solve one of the most
fundamental issues related to the Web: in order for computers to be able to use
information from the universe of web pages, information on a web page must be
put into a meaningful context. For
example, a web search on the word “rose” brings up pages related to flowers and
colors. If each page also contained a
description of how the main topics of the page fit into an ontology, then
search engines could detect if the page discussed colors or flowers.
The standardized use of a language for
ontology and its deployment on web pages would greatly expand the usefulness of
the web. In fact, the Worldwide Web
Consortium (W3C) is creating such a Web standard for an ontology language as
part of its effort to define semantic standards for the Web. The Semantic Web is the abstract
representation of data on the Web, based on the Resource Description Framework
(RDF) and it related technologies RDF Schema (RDFS) and the Web Ontology
Language (OWL). By using RDF/RDFS/OWL,
integrated and unified information systems could be made up of thousands of
subsystems all with their own internal semantics, but bound together in a
common ontology.

Figure ‑1 RDF, RDFS, and OWL Build on Existing W3C
Work
RDF/RDFS/OWL, particular ways of using the
extensible markup language (XML), provide an application-independent way of
representing information. The RDF
related technologies build upon existing W3C work as illustrated in Figure 1. RDF/RDFS/OWL
have been designed to express semantics and as opposed other technologies as
illustrated in Figure 2.

Figure ‑2 The Tree of Knowledge Technologies
RDF uses XML to define a foundation for
processing metadata (metadata is information about data and is separate
from the data itself). RDF can be
applied to many areas including data warehousing, as well as searching and
cataloging data and relationships (metadata).
RDF itself does not offer industry specific vocabularies. However, any industry can design and
implement a new vocabulary.
RDF’s data model provides abstract conceptual
framework for defining and using metadata.
The basic data model consists of three object types
·
Resource : All things described by RDF
expressions are called resources, e.g. it can be an entire web page, a specific
XML or XML document or collection of whole page
·
Properties: property is a specific aspect that
describes this resource. Each property has a meaning,
·
RDF Statement (triples): A resource together
with a named property and its value.
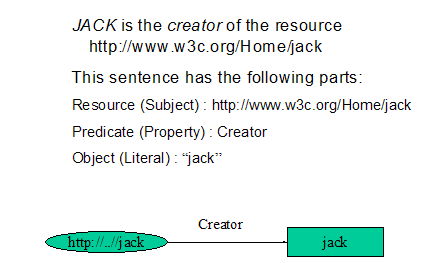
Figure ‑3
RDF Example
RDF
Schema (RDFS) builds on RDF and provides more support for standard semantic
concepts such as what a class, class property, and class association are as
illustrated in Figure 4.
Figure ‑4 RDFS Example
The Web Ontology Language (OWL) builds on RDF
and RDFS to add the ability to express what is common and what is different
between different ontologies. For
example, OWL can be use to express the differences between two different energy
market ontologies defined by Nerc and ETSO for example. Specifically OWL adds:
·
Class
Axioms
o
oneOf
(enumerated classes)
o
disjointWith
o
sameClassAs
applied to class expressions
o
rdfs:subClassOf
applied to class expressions
·
Boolean
Combinations of Class Expressions
o
unionOf
o
intersectionOf
o
complementOf
·
Arbitrary
Cardinality
o
cardinality
o
minCardinality
o
maxCardinality
·
Filler
Information
o
hasValue
Descriptions can include specific value information
Figure ‑5
OWL Example
Since
the RDF related technologies are equally suited for structured, as well as
unstructured data, like the documents described previously, they are
ideal for use as the unifying mechanism for describing data for an asset
analysis platform. These technologies
appear to be the key for next generation knowledge/content management
solutions. Using RDF/RDFS/OWL, it will
be possible to use a single information management infrastructure across all
utility information resources.
Conclusion
As described above, the most significant data
management issue revolves around how to discover the format and meaning of
data. XML and RDF provide promising ways
to describe data. However, just having
mechanisms for describing the format and meaning of data is not enough – one
must also have an understanding of the data itself as well as a means to
connect systems together in order to operate on the data. These last two tasks can be described as
technologies for understanding what data is passed and how data
is passed between systems. While XML and
RDF help us a great deal we still need Common Information Model that get
encoded using XML and RDF and Generic Interfaces complementary to XML and RDF
for application integration and data integration tasks.
If discovery of information emerges as a key
feature that a technology must support to limit configuration tasks and
increase the understanding of data, what field device protocols best support
discovery? This section discusses these
issues as they pertain to field device protocols.
Comparison
of DNP3 and IEC61850
The International Electrotechnical Commission
(IEC) Technical Committee 57 (TC57) began releasing the IEC60870-5
series of standards related to data communication protocols for intelligent
electronic devices (IED) over serial links in 1990. After several more years of
effort, the application layer protocols needed to build actual implementations
of these standards had not been finalized. Necessarily, the substation automation
division of GE-Harris in Calgary, Alberta, Canada took the existing IEC work,
finished it internally, and released it as the Distributed Networking Protocol
Number 3 (DNP3) in 1993. Simultaneously, GE-Harris formed a non-profit
organization with open membership and transferred the ownership of and
responsibility for DNP3 to this group called the DNP Users Group. The DNP Users
Group attracted a critical mass of North American suppliers and utilities as
members and supporters that resulted in DNP3 becoming widely used in North
America. The IEC TC57 continued its work and did finally release the
application protocols for serial link based communications as IEC60870-5-101 in
1994.
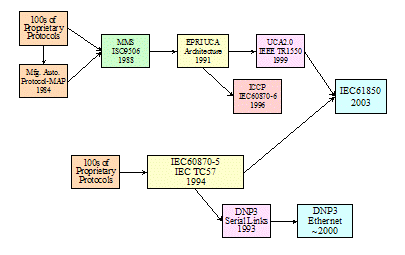
Figure ‑6
The
Evolution of DNP3 and IEC61850
Both DNP3 and IEC60870-5-101 specified a
master-slave protocol for point-to-point serial links. A major consideration in
the early 90s was the relatively high cost of bandwidth for the communications
channels available to utilities. The byte efficiency of DNP3 and IEC60870-5-101
made them suitable for immediate applications in these low bandwidth
environments. Since then, as bandwidths costs have declined and as the use of
high-speed networking technology like Ethernet became widespread, even in
substations; both the IEC and DNP3 have offered Ethernet based versions of
these protocols that transmit the same byte sequences used on serial links over
high-speed local area networks (LAN)
using the TCP/IP
or UDP/IP protocols over Ethernet.
The resulting IEC standards had minor
differences with DNP3. Although seemingly minor, these differences resulted in
incompatibilities that have fragmented the market. DNP3 became very widely used
in North America and in other countries where North American suppliers had
strong market share, while IEC60870-5-101 became dominant in Europe and other
countries where European suppliers were dominant.
In 1991, the Electric Power Research
Institute (EPRI) released a specification entitled the Utility Communications
Architecture (UCA). UCA provided an
overall architecture for communications within the utility enterprise and
described the communications requirements for each application domain within
the utility enterprise. The original UCA 1.0 document referred to specific
pre-existing protocols that could be used within each application domain but
did not provide sufficient implementation details for developers to build
products around. In the distribution and transmission domains, the UCA1.0
specification suggested the use of the Manufacturing Message Specification (MMS) per
ISO9506 (released in 1988) for real-time communications. MMS was
already used in some industrial automation applications at the time and offered
high-level object oriented communications for real-time data access and
supervisory control for LAN
based devices.
In 1992, EPRI then began a process of
creating utility communications standards for real implementations in several
application spaces. The first was for control center to control center
application to replace aging bi-synchronous protocols used for inter-utility
data exchange that was needed to support the rapidly developing competitive
energy market. This resulted in the Intercontrol Center Communications Protocol
(ICCP). EPRI submitted the ICCP work to IEC TC57 Working 7 (WG07) resulting in
the IEC60870-6 TASE.2 standard in 1996. Today, ICCP-TASE.2 is widely used
world-wide for inter-utility data exchange and power plant dispatching.
Although profiles for the IEC60870-5 standards were developed for this same
application space (IEC60870-5-102), the ICCP-TASE.2 standard is more widely
used particularly in large-scale systems in North America, South America, Asia,
and Europe.
The second effort EPRI started was to fully
develop a single unified communications protocol based on the UCA1.0
recommendations for both distribution automation and substation automation
applications. This resulted in the UCA 2.0 specification which was published as
an IEEE technical report TR1550 in 1999. While the EPRI work was nearing
completion the IEC TC57 working group that developed the IEC60870-5 protocols
(WG10, WG11, and WG12) began work on upgrading the older IEC60870-5 standards
to address the needs of modern substations using LAN technologies
like Ethernet and TCP/IP.
The result was the release of IEC61850 in 2003 that integrated the European
experience with IEC6087-5 with the North American efforts of UCA2.0 to create a
single unified international standard for substation automation utilizing
modern high-speed networking technology.
IEC61850 specifies a set of communications
requirements for substations, an abstract service model for commonly required
communications services in substations, an abstract model for substation data
objects, a device configuration language based on XML, and a mapping of these
abstract models to the MMS
application layer protocol running over TCP/IP
based Ethernet networks. The
virtualized architecture of the IEC61850 standard (whereby an abstract model
for services and objects are mapped onto a specific protocol profile) provides
a flexible approach that could, theoretically, be mapped onto other protocols
in the future.
The most significant differences in the roots
of DNP3 (including IEC60870-5) and IEC61850 is that DNP3 was originally defined
as an RTU protocol for low-bandwidth point-to-point serial link requirements
that was later migrated for use over high-speed substation networks. IEC61850
was designed specifically for application in the substation LAN
environment. Most of the technical differences between these protocols can be
directly traced to these different roots. Some would argue that having a single
simpler protocol work over both serial links and LAN can
reduce costs by reducing the learning curve associated with deploying new
protocols. Others will argue that using simple serial link protocols originally
intended for low bandwidth environments does not take advantage of the
capabilities of modern networks and IEDs and results in lower performance with
higher configuration and maintenance costs.
Comparison
of Communications Profiles
Although DNP3 was originally developed for
serial link profiles, the DNP Users Group (and IEC TC57 for the IEC60870-5
standards) have released communications profiles that enable DNP3 to operate
over Ethernet based networks. While the UCA2.0 specification provided both
serial link and Ethernet based profiles, the IEC61850 standard provides
profiles for Ethernet based networks only. The comparison provided here will
focus on the Ethernet based profiles for DNP3 and IEC61850.
There are two types of Ethernet based
communications profiles supported by these standards: connection-oriented and
connectionless. A connection-oriented profile is used to support directed communications
where there is a virtual connection between two communicating entities and only
two entities per communications session. Connectionless profiles are typically
used for multicast messaging where a single transmitted message can be received
by multiple receivers. Both IEC61850 and DNP3 offer separate profiles for
connection-oriented and connectionless communications.
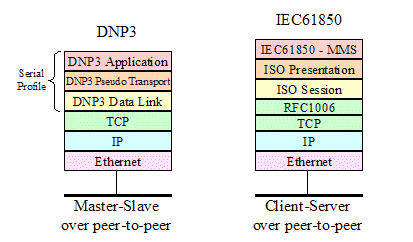
Figure ‑7
Profile Comparison: Directed Communications – Connection-oriented
For the connection-oriented profiles, both
IEC61850 and DNP3 utilize TCP/IP
protocols for the transport and network layers. For the DNP3 profile, the same
master-slave protocol that was developed for the serial link profile, including
DNP3 Pseudo Transport and Data Link protocols, is sent over TCP. TCP
connections are initiated between the master and each slave on the network.
DNP3 slaves listen on a defined TCP port
for incoming messages from the master. Upon receipt they would respond to the
master appropriately. Like in a serial based system, the DNP3 data link is used
to coordinate the activities between masters and slaves. There are DNP3 data
link protocol packets that are received by slaves that tell them when they can
either respond to a message from the master or when they can send unsolicited
data for reporting purposes. Although the coordination of this activity is not
strictly required by the underlying TCP/IP
stack, this approach enables existing master and slave software to be used for
both serial and LAN
profiles without a lot of modification. The result is a master-slave protocol
running on the peer-to-peer TCP/IP
network.
IEC61850 uses an Internet Engineering Task
Force (IETF) standard called RFC1006 for mapping the IEC61850 and MMS
protocol packets over a TCP/IP
network for connection-oriented communications. The RFC1006 standard was
developed by IETF for mapping ISO/OSI
application level protocols, like the MMS that
IEC61850 is based upon, to TCP/IP.
In IEC61850 a calling node issues a connection request to a remote called
node. Called nodes listen for incoming connection requests on a defined TCP
port. Once the communications session has been established either side may
assume the client or server role and send data and/or requests over the
connection independently of the other side as long as the connection is up.
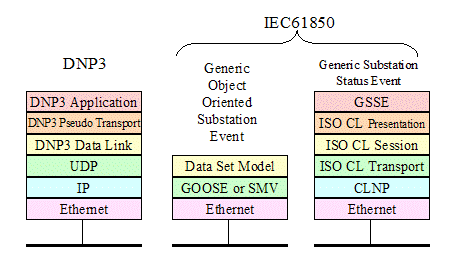
Figure ‑8
Profile Comparison: Multi-cast communications – Connectionless
For connectionless communications, DNP3 and
IEC61850 differ more substantially. As with the connection-oriented profile,
the DNP3 profile for connectionless essentially runs the DNP3 serial link
profile over an Ethernet based profile. In this case, the Unsolicited Datagram
Protocol (UDP) protocol is used instead of the TCP
protocol. UDP is a connectionless non-reliable transport protocol that provides
connectionless communications over IP based networks. Reliable message delivery
is provided by the DNP3 Pseudo Transport and Data Link protocols that are used
in this profile. Rather than listening on a defined TCP port
for incoming messages from a master, DNP3 slaves listen to a multi-cast IP
address for messages from the master. Both slaves and masters need to be
configured with the multi-cast IP address. Because UDP is not a reliable
message transport protocol that supports segmentation and reassembly of
packets, there are some limitations about how data can be transmitted using
this profile. For some applications, these limitations may not be significant
and there are successful implementations of this profile.
For IEC61850, and unlike DNP3, the
connectionless multi-cast profile serves a fundamentally different purpose than
the connection-oriented profile. With IEC61850 the connection-oriented profile
is used at the station level for data exchange between two specific nodes. In
the connectionless profile IEC61850 uses the multi-cast profiles to send
several fundamentally different types of messages to multiple nodes
simultaneously: 1) status information (Generic Substation Status Event – GSSE)
regarding the state of an IED, 2) data set of IEC61850 objects (see discussion
of object models later), and 3) sensor information via the Sampled Measures
Values (SMV) approach
of IEC61850-9-2. GSSE is typically used by protective relays to broadcast their
current status (e.g. blocked, tripped, etc.) quickly (≤4 milliseconds) so that other
devices can use that information in complex protection algorithms. A Generic
Object Oriented Substation Event (GOOSE) is used to communicate commonly used
information (e.g. three phase voltage measurements) to multiple nodes
simultaneously. SMV is
used to send raw measurements from intelligent sensors to multiple nodes
simultaneously that enables a digital replacement for analog current and
voltage transformers.
In summary, the DNP3 profiles enable the
transmission of the same protocol originally developed for serial links over
either connection-oriented or connectionless LANs. This results in the
essential character of the protocol being preserved (i.e. master-slave) while
supporting the very significant performance improvements that the use of modern
LAN
technology affords. The only real difference in the DNP3 connection-oriented
versus connectionless environments is that the latter avoids the small TCP
overhead of maintaining separate TCP
connections between each master and slave. The IEC61850 connection oriented
profiles offer a similar capability as the DNP3 profiles offer for basic station
level and SCADA services using a client-server approach that enables
independent communications between nodes. IEC61850 connectionless profiles
support other capabilities for specific substation applications that go beyond
the original intent of DNP3.
Comparison
of Service Models
The services supported by DNP3 is large
subset of that offered by IEC61850. This is not surprising since both are
intended for similar applications in substation automation. In several areas
where either DNP3 or IEC61850 has a capability not supported by the other, it
is still possible to implement these services by combining other services. For
instance, event logs can be implemented using files in DNP3 even though the
DNP3 standard does not specify how to implement event logs. While the advantage
of having the standard define these capabilities directly might be lost, the
basic functionality is still available.
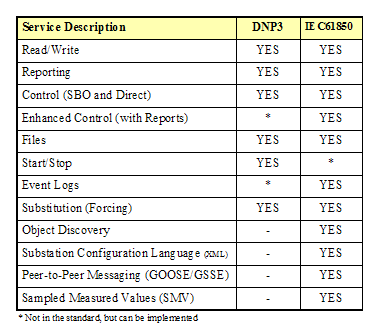
Figure ‑9
Service Comparison
There are services that IEC61850 offers that
cannot be practically supported using the current version of DNP3. These
services include object discovery, Substation Configuration Language (SCL),
GOOSE, GSSE, and SMV.
Because these high-level (object discover) or very high-performance (GOOSE,
GSSE, and SMV)
services were not practical for low-bandwidth serial link applications, they
were never a part of DNP3’s origins and, therefore, were not available for the LAN
based profiles that were developed for DNP3. There are work items within the
DNP Users Group to develop a mapping between the abstract models of IEC61850 to
DNP. However, such a mapping would require protocol changes to support these
additional services that could not be implemented using the DNP3 protocol as it
is defined today.
Comparison
of Object Models
Both IEC61850 and DNP3 define various objects
for representing power system data. The DNP3 object model is based on a
traditional remote terminal unit (RTU) device model. A traditional RTU is
general purpose device capable of collecting I/O signals in a variety of
formats (digital, analogy, state, etc.) and communicating those I/O points
using a given SCADA protocol, like DNP3. Because RTUs were traditionally
general purpose, it was the user or system engineer that determined the
specific function a specific I/O point represented when they wired that I/O
point within the substation. For example, an RTU would have a variety of analog
and digital inputs. It was typically the user that wired those inputs to
specific current and voltage transformers or specific breakers that created the
“mapping” between these I/O points and specific functions in the substation.
Therefore, when the engineer wanted to access the I/O for a given bus voltage
by communicating to the RTU from a remote site via some protocol, they would
have to have either a wiring diagram, or other document, that described where
the desired voltage was wired into the RTU in order to access that I/O point
via the RTU protocol.
The DNP3 data model is based on a similar
structure. A DNP3 object description is comprised of three different parts:
·
Object Number. The object number
specified the type of data point using a numerical value. For example, object
number = 1 would represent a Binary Input Static data point, object number = 2
would represent a Binary Input Event data point, and so on.
·
Variation Number. The variation number specified which optional
parameters would be present for a given data point of a specific object number.
For instance, variation number = 1 would mean that the data point included
status, variation number = 2 meant that the data point did not include status,
and so on.
·
Index Number. The index number refers to
a specific instance of an object of a given object and variation. For instance,
if a device supported 16 binary input static objects, the index number to
access one of these was 0-15.
·
Device Profile. In addition to the
description of the data points as defined above, the DNP Users Group also
specified device profiles for common devices that specified which objects
should be implemented for a given type of device with recommendations for which
object and variation numbers should be used for various types of signals that
are commonly needed in these applications.
The result is that DNP3 specified a broad set
of data objects and device types sufficient to provide interoperability for a
large number of applications and device types in power systems. Additional
profiles are added as needed by the user community. Furthermore, the use of
small 8-bit numbers to represent object and variation types and compact index
numbers provided a very byte-efficient mechanism for specifying a data point.
This allowed DNP3 to maximize the number of data points that could be fit into
a single DNP3 data frame. As described earlier, this byte efficiency was
critical to the effectiveness of DNP3 as a solution for low-bandwidth serial
links.
The IEC61850 data model is an object oriented
model that not only defines the basic data types for common data points, but
also rigorously defines the naming conventions used and how the data is
organized into functional groupings called logical nodes. IEC61850 does
not use compact numbers to describe data points. Instead, IEC61850 uses names
that specify a fixed hierarchical organization for the data to describe each
data object. The name specifies not the only the way you access the data point
via the protocol, but it also defines its functional characteristic within the
device. In other words, the engineer can determine that a given point is a
voltage without having to know how the device is wired. The IEC61850 data model
consists of the following concepts:
·
Logical Device. The IEC61850 object model
enables a single physical device to represent data for multiple logical devices
such as might exist in a data concentrator application. This name is typically
defined by the user or supplier. IEC61850 requires at least one logical device
with a name of “LD0” to be present to hold data common to all logical devices
such as device identity information.
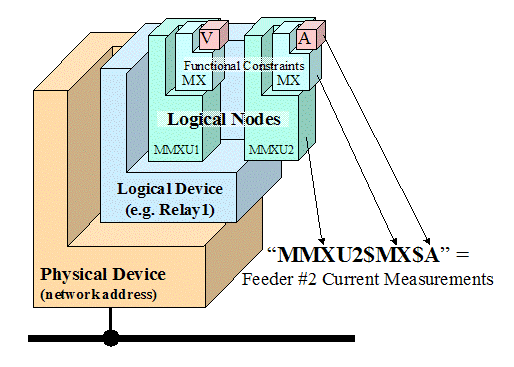
Figure ‑10
IEC61850 Object Model
·
Logical Node. Specifies a grouping of
data objects that are functionally related. For instance, measurements are contained
in logical nodes with the name “MMXU”, data related to a switch controller
function will be contained in logical nodes with the name “CSWI”, breaker data
will be contained in a logical node named “XCBR”, and so on. Multiple instances
of the same logical node are delineated by a suffix number (MMXU1, MMXU2,
etc.). Logical nodes that are related to each other (the switch controller
(CSWIx) associated with a given breaker (XCBRx)) are associated to each other
in the name using a user defined prefix.
·
Functional Constraint. While not a formal part of the object models
for IEC61850, the mapping of IEC 61850 to MMS
contained in part 8-2 introduces this name to group together data objects with
similar functions within the logical node. For instance, “MX” designates
measurements and “DC” designates descriptions, etc.
·
Data Object. The data object name
specifies the data desired. For instance, “V” specifies voltage and “A”
specifies current, etc.
·
Attributes. These specify the individual
elements that comprise a data object. For instance, “PhsAf” specifies the
floating point value for phase A in a wye-connected measurement, “q” specifies
quality flags, “t” specifies the time stamp, etc. The IEC61850 standard defines
the data types (integer, floating point, binary, time, etc.) for all allowable
attributes.
Per the mapping of IEC61850 to 8-1, to create
an object name you would take each element from the Logical Node down in the
hierarchy separated by dollar signs (“$”). Therefore, the floating point value
of the phase A voltage in the first measurement unit of a given device would
be: MMXU1$MX$V$PhsAf. A power system engineer familiar with the IEC61850 naming
convention can determine which data point contains the data they are interested
in by examining the same name that is used to access the data via the protocol.
The name for the same functional objects is mostly the same in any given device
regardless of the brand or type of device.
Additionally, IEC61850 includes a Substation
Configuration Language (SCL per
IEC61850-6) that can be used to express the configuration of all the data
objects in a given device using XML. An SCL file
will contain a description of all the logical devices, logical nodes, etc. that
are defined for a given device. The SCL file
can be used for many purposes that can significantly lower costs and improve
productivity including: enabling users to create specifications for devices
that can be used for RFPs to ensure the equipment they purchase meets their
functional requirements, automated tools can be developed to automatically
configure devices with specific objects, configuration information on devices
can be exchanged among devices improving the interchangeability of devices and
applications, and many other future uses limited only by the creativity of
users and suppliers.
Conclusion
In many ways, a direct head to head
comparison between DNP3 and IEC61850 is not fair, and depending on the
circumstance, might not even be valid. It is a classic apples and oranges
comparison. You can use apples to make applesauce and you can use oranges to
make orange juice. But there is no reason that you can’t enjoy a glass of
orange juice while eating a bowl of applesauce. The same is true with respect
to DNP3 and IEC61850: they are not mutually exclusive. Each protocol has
characteristics that will make it optimal for a given set of application
constraints. Each was designed to be optimized for a given set of requirements.
This does not mean that neither can be used outside of its optimal space nor
does it mean that only one or the other can be used at any given time. The byte
efficiency of DNP3 makes it an excellent choice for bandwidth constrained
applications in distribution like pole-top devices or where existing systems
already provide DNP3 connectivity. The
high-level object models and high-performance services of IEC61850 will make it
an excellent choice where large numbers of devices must be configured, where
the number of communicating entities is difficult to fix or is constantly
changing, and where changes in device configuration is frequent cause
maintenance problems in existing applications. Any well-designed system will
utilize each/both DNP3 and IEC61850 as appropriate to maximize the benefits and
minimize the costs for implementing the systems needed by users.
Key technologies
for the integration and analysis of control center data are three IEC
standards: WG 13’s 61970 Common Information Model (CIM) and Generic Interface
Definition (GID) as well as WG 14’s 61968 messaging
standards. How these standards fit in
with other TC 57 standards is illustrated in Figure
11
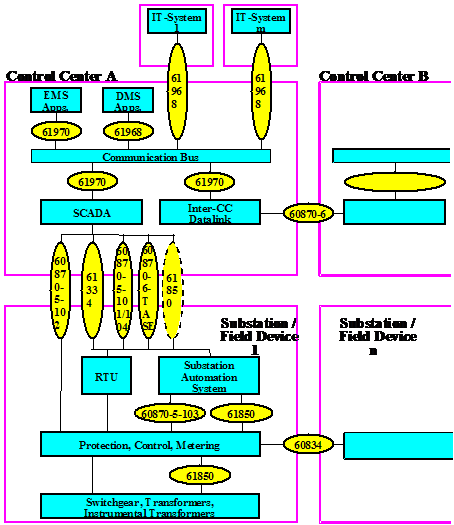
Figure ‑11 TC 57 Standards
IEC CIM
The CIM contains
object types such as substations, breakers, and work orders as well as other
data typically found in an EMS,
SCADA, DMS, or work, and asset management system. More recently, the CIM is
being extended to include transmission reservation and energy scheduling
information. The CIM was originally developed as part of the EPRI Control
Center Application Programming Interface (CCAPI) project and later standardized
by IEC TC57 WG13 as part of the IEC61970 series standards for control centers.
The CIM standard includes information associated with control center
applications such as:
·
Energy Management Systems (EMS)
o
Topology Processing
o
State Estimator
o
Power Flow
·
Security Analysis
·
Supervisory Control and Data Access Systems
(SCADA)
·
Network planning
IEC TC57 WG14 has
extended the CIM in their IEC61968 standard for Distribution Management Systems
(DMS) related functions. IEC61968 added information models associated with
operational support applications such as:
·
Asset Management Systems (AMS)
·
Work Management Systems (WMS)
·
Construction Management
·
Distribution Network Management
·
Geographic Information Systems (GIS)
·
Outage Management
The CIM describes
real world objects in terms of classes, attributes and relationships. For
example, the diagram below depicts the relationship between a set of CIM
classes per IEC61970. A substation can contain voltage levels. Voltage levels
can contain equipment. Breakers and Transformers are subtypes of a more general
class called Conducting Equipment. Breakers have terminals that are associated
with measurements. Transformers have windings that are also associated with
measurements. And so on.
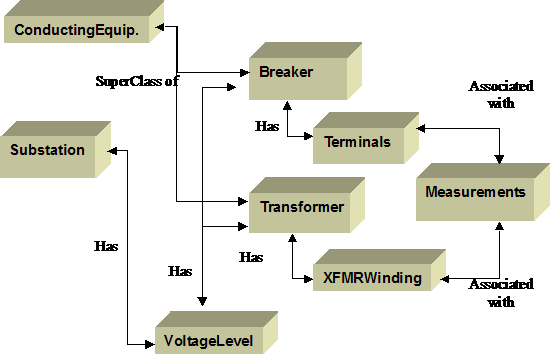
Figure
‑12 Simplified Fragment of CIM Power System Model
This diagram above
does not illustrate all the possible associations specified in CIM. For
example, substations, breakers, and transformers may also be directly
associated with measurements. The
diagram below illustrates a very simplified view of some of the CIM classes
added by IEC61968:
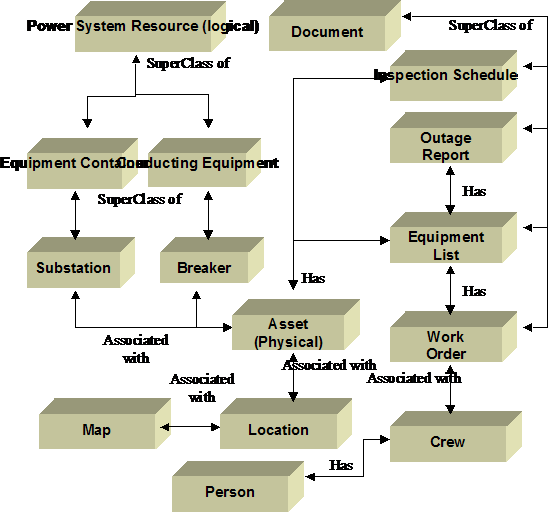
Figure
‑13 Simplified Fragment of CIM Asset/Work Model
In the diagram
above, Power System Resource is the parent class of all logical equipment, such
as circuit breakers, and equipment containers, such as a substation. In the
CIM, the term “asset” refers to a physical object. Assets are associated one to
one with logical equipment. Assets exist at a location that can be represented
on a map. Elsewhere, the IEC61968 CIM also defines a parent document class.
Outage reports, equipment lists, work orders, and inspection schedules are sub
types of the document class. An outage report contains an equipment list that
refers to one or more assets. And so on.
The CIM is defined
as a set of Class Diagrams using a model language called the Unified Modeling
Language (UML). UML is an object-oriented modeling language used for system
specification, visualization and documentation. UML is a way of describing
software with diagrams and is a language that both users and programmers can
understand. The CIM itself is maintained in a software information modeling
tool called Rational Rose. This is just one of many tools supporting UML.
The CIM is partitioned into a set of packages.
Each package is a way of grouping related model elements. Each package in the
CIM contains one or more class diagrams showing graphically all the classes in
that package and their relationships to other classes. Measurements are defined in the Meas
package, which contains entities that describe dynamic measurement data
exchanged between different applications.
The CIM class
diagrams describe the types of objects in the system and the various kinds of
static relationships that exist among them. There are three principle kinds of
static relationships:
·
Associations (A Terminal is connected to a
connectivity node)
·
Generalization and subtypes (A switch is a type
of conducting equipment)
·
Aggregation (A winding is part of a transformer)
Generalization or
inheritance is a powerful technique for simplifying class diagrams. The primary
use of generalization in the CIM is shown in figure below.
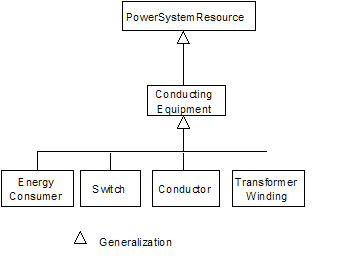
Figure
‑14 Generalizations for power system resource and conducting
equipment
By defining a
PowerSystemResource class, the attributes and relationships for this class can
be inherited by all the other subclasses. The PowerSystemResource class is used
to describe any physical power system object or grouping of power system
physical objects that needs to be modeled, monitored or measured. All the
subclasses of PowerSystemResource inherit the following relationships:
·
PowerSystemResource “measured by” Measurement
·
PowerSystemResource “owned by” Company
·
PowerSystemResource “member of” PowerSystemResource.
The
ConductingEquipment class is used to define those objects that conduct
electricity. As shown in the figure below,
the following associations are used to specify the connectivity of these
objects:
·
ConductingEquipment “has” Terminals
·
Terminal “is connected to” ConnectivityNode
·
Connectivity Node “is member of” TopologicalNode
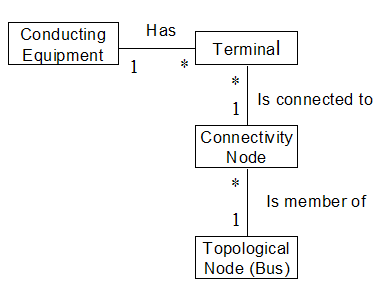
Figure
‑15 Defining connectivity for conducting
equipment
The transformer
model in the figure below illustrates the use of Aggregation. The aggregation
relationship specifies that:
·
A Transformer “has” one or more windings
·
A Transformer Winding “has” 0, 1 or 2 Tap
Changers
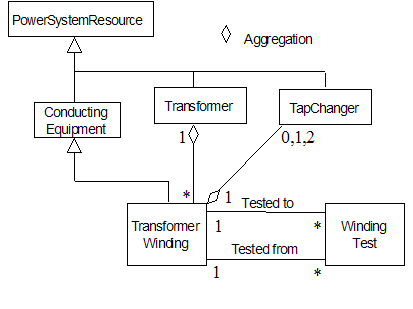
Figure
‑16 Transformer model illustrating use of aggregation
In the CIM, the
aggregation relationships in the figure above would be specified using the
PowerSystemResource “is member of” PowerSystemResource relationship. Equipment
can be grouped into zero, one, or several containers. For example, a switch
could have the following relationships:
·
Switch “is member of” substation
·
Switch “is member of” transmission line
·
Switch “is member of” Feeder
Comparison of the CIM and the 61850
Object Model
There is often
understandable confusion about the similarities and differences between the
IEC61850 device object models and the IEC61970 CIM UML-based Models. Both are
abstract models of information; both involve utility operations; both were
developed in the IEC TC57 standards organization in two working groups with
some common membership. Both object models are defined using XML schemas. Yet
despite these similarities, they have not (yet) been “harmonized” to work
together as a seamless whole.
Figure 17 provides an overview of the domains of the two
standards.

Figure
‑17: IEC61850 Models and Connections with
IEC61970 Models
IEC61850
As can be seen in
this figure, the IEC61850 models are predominantly in the field. These IEC61850
models are of physical field devices, such as circuit breakers,
protection relays, capacitor controllers, and, in recent work, distributed
energy resources such as wind turbines, diesel generators, and fuel cells. The
IEC61850 standard contains a number of parts, including the actual Object
Models (OM), Service Models (SM), and mappings to different Communication
Protocols (CP).
The Object Models
are “nouns” with pre-defined names and pre-defined data structures. Objects are
the data that is exchanged among different devices and systems. The OM
structure from the bottom up is described below:
·
Standard
Data Types: common digital formats such as Boolean, integer, and floating
point.
·
Common
Attributes: predefined common attributes that can be reused by many
different objects, such as the Quality attribute. These common attributes are
defined in IEC61850-7-3 clause 6.
·
Common
Data Classes (CDCs): predefined groupings building on the standard data
types and predefined common attributes, such as the Single Point Status (SPS),
the Measured Value (MV), and the Controllable Double Point (DPC). In essence,
these CDCs are used to define the type or format of Data Objects. These CDCs
are defined in IEC61850-7-3 clause 7.
·
Data
Objects (DO): predefined names of objects associated with one or more
Logical Nodes. Their type or format is defined by one of the CDCs. They are
listed only within the Logical Nodes. An example of a DO is “Auto” defined as
CDC type SPS. It can be found in a number of Logical Nodes. Another example of
a DO is “RHz” defined as a SPC
(controllable single point), which is found only in the RSYN Logical Node.
·
Logical
Nodes (LN): predefined groupings of Data Objects that serve specific
functions and can be used as “bricks” to build the complete device. Examples of
LNs include MMXU which provides all electrical measurements in 3-phase systems
(voltage, current, watts, vars, power factor, etc.); PTUV for the model of the
voltage portion of under voltage protection; and XCBR for the short circuit
breaking capability of a circuit breaker. These LNs are described in IEC61850-7-4
clause 5.
·
Logical
Devices (LD): the device model composed of the relevant Logical Nodes. For
instance, a circuit breaker could be composed of the Logical Nodes: XCBR, XSWI,
CPOW, CSWI, and SMIG. Logical Devices are not directly defined in any of the
documents, since different products and different implementations can use
different combinations of Logical Nodes for the same Logical Device. However,
many examples are given in IEC61850-5.
IEC61970
In contrast, the
IEC61970 CIM models are predominantly in the control center, where the core
model is of the relationships among the power system elements, such as
what transmission lines are connected to which substations, which are connected
to which circuit breakers and distribution lines. The CIM provides an abstract
model of power systems, including physical configuration (wires), political
aspects (ownership hierarchy), market aspects, and others. It is defined in UML
and can be represented in XML. The GID, also defined as part of IEC61970, provides
abstract services for exchanging objects, including read/write and
publish/subscribe. The fact that these are abstract
means that they are technology independent, and can be implemented using
different technologies in different installations.
CIM limitations
include that the CIM model is static, so that definitions of data exchanges in
CIM format are not a part of the CIM model and must be defined externally for
each implementation. No mechanism is included in the standard to define data
exchanges dynamically, although the Component Interface Specifications describe
some specific types of CIM objects to be exchanged for specific functions. In
addition, CIM is focused on transmission power system and asset management
applications, and therefore, still requires extensions for other aspects of
power system operations.
IEC61850 Configuration
Language and the CIM
The concept of a configuration
language is that the configuration of the substation can be modeled
electronically using object models, not just the data in the substation. This
model of the substation configuration allows applications to “learn” how all
the devices within a substation are actually interconnected both electrically
and from an information point of view.
The Substation
Configuration Language (SCL), IEC61850 Part 6, defines the
interrelationship of the substation equipment to each other and to the
substation itself. Although the substation object models define each of the
devices in the substation, these device models do not define how the models are
interrelated. Therefore Part 6 was developed to provide a tool for defining the
substation configuration.
The SCL uses a standard file format for exchanging
information between proprietary configuration tools for substation devices.
This standard is based on Extensible Markup Language (XML), and draws on the
data modeling concepts found in the other parts of IEC 61850, and the
capability of the IEC 61850 protocols to “self-describe” the data to be
reported by a particular device.
The SCL is therefore almost identical in concept to
the CIM: it is identifying the relationships
among the different devices within the substation. It is exactly here where the
main “conflict” between the two standards emerges.
Harmonization
In one sense,
these differences between the two models are as great as those between apples
and oranges. However, it is clear that both are needed and that each
supplements the capabilities of the other. In addition, if both are implemented
in a utility, they must interface with each other and function as an integrated
whole.
The IEC TC57 has
in fact undertaken to harmonize the two models as illustrated in Figure 18.

Figure
‑18 Proposed Harmonization of 61850 and 61970
Information Models
In this on-going
harmonization work, two Use Cases were identified as being important in
illustrating the key harmonization issues:
·
‘Retrofit of the equipment in a substation (with
addition of a new line and transformer)’
·
‘Real-Time information exchange between 61850
devices and the Control Center / Office’
The first Use Case
assumes the use of the Substation Configuration Language in the IEC61850 world,
and addresses the harmonization between that and the CIM. Since both SCL and CIM use XML, some preliminary work has
suggested adding SCL to the CIM as another UML sub-model, with
the IEC61850 Logical Nodes identified via XML tags that have been harmonized
between the CIM and SCL. Some naming issues remain.
The second Use
Case addresses a secondary “conflict” which is that the CIM defines all
measurements as “PowerSystemResource” combined with a “MeasurementType” with no
further clarification, while IEC61850 defines each value with a unique name.
Although not formalized yet, the solution seems to be to use the CIM AliasName
in the MeasurementType CIM table to refer to the IEC61850 names.
61970 Generic Interface Definition
Without a means to
discover what data an application processes, plug and play is nearly impossible
to achieve. To address these impediments
to plug and play and the need for a common exchange mechanism, or “how” data is
exchanged, WG13 is in the process of adopting a series of interface standards
called the Generic Interface Definition (GID). The GID is an umbrella term for four interfaces:
·
Generic Data Access (GDA) – A generic
request/reply oriented interface that supports browsing and querying randomly
associated structured data – including schema (class) and instance information.
·
Generic Eventing and Subscription (GES) – A publish/subscribe oriented interface
that supports hierarchical browsing of schema and instance information. The GES is typically used as an API for publishing/subscribing to XML formatted
messages.
·
High Speed Data Access (HSDA) – A request/reply
and publish/subscribe oriented interface that supports hierarchical browsing
and querying of schema (class) and instance information about high-speed data.
·
Time Series Data Access (TSDA) – – A
request/reply and publish/subscribe oriented interface that supports
hierarchical browsing and querying of schema (class) and instance information
about time-series data.
Table 1 below organizes the GID functionality into a simple matrix:
|
Table ‑1
Matrix Of GID
Functionality
|
|
|
Generic
|
High Speed
|
Time Series
|
|
Request/Reply
|
GDA
|
HSDA
|
TSDA
|
|
Publish/Subscribe
|
GES
|
HSDA
|
TSDA
|
Applications use
the standard interfaces to connect to each other directly or to an integration
framework such as a message bus or data warehouse. The GID interfaces allow applications to be written
independently of the capabilities of the underlying infrastructure.
The GID can be realized using a variety of
middleware technologies including:
·
RPC/API based CORBA, COM, Java, or C language
specializations
·
W3C Web Services/XML/HTTP based
Regardless if
these interfaces are implemented as an API or on the wire, the GID provides the following key functionality
required for creation of a plug and play infrastructure:
o
Interfaces are generic and are independent of
any application category and integration technology. This facilitates
reusability of applications supporting these interfaces.
o
Interfaces support schema announcement/discovery
– The schemas are discoverable so that component configuration can be done
programmatically at run time. Programmatically exposing the schema of
application data eliminates a great deal of manual configuration.
o
Interfaces support business object namespace
presentation – Each component describes the business object instances that it
supports within the context of a common namespace shared among all applications
such as a power system network model like the EPRI Common Information Model
(CIM). It is not enough to merely expose the application data schema, one must
also expose what specific breakers, transformers, etc., that an application
operates on. This also eliminates manual
configuration as well as provides a means for a power system engineer to
understand how enterprise data is organized and accessed.
The advantage of
using generic interfaces instead of application-specific ones cannot be over
emphasized. The benefits of using
generic interfaces include:
The interfaces
developed are middleware neutral and were designed to be implemented over
commercially available message bus and database technology. This means a single wrapper can be used
regardless on the technology used to perform integration.
As application
category independent, the same interfaces are used to wrap any
application. This means that new
wrappers do not need to be developed every time an application is added to the
system.
·
Creates a consistent and easy to use integration
framework by providing a unified programming model for application integration.
·
Enhances interoperability by “going the last
mile”. Agreement on the “what” of data is not enough to ensure component
interoperability. We also need to standardize on “how” data is accessed. To
provide a simple analogy, we standardize on a 110/220 volt 60 hertz sine wave
for residential electrical systems in the US. This is a standardization of
“what”. However, we also standardize the design of the plugs and receptacles.
This is a standardization of the “how”. The standardization of plugs and
receptacles means that we don’t need to call an electrician every time we want
to install a toaster. Similarly with software, standardizing on the interface
means a connector does not need to be created from scratch every time we
install a new application.
·
Since application vendors can “shrink wrap” a
CIM/GID compliant wrapper, the use of the CIM and GID can lower the cost of integration to
utilities by fostering the market for off-the-shelf
connectors supplied by application vendors or 3rd
parties. The time and money associated with data warehousing/application
integration wrapper development and maintenance is high. Typically, most money
spent on integration is spent on the wrappers. An off-the-shelf CIM/GID wrapper can replace the custom-built
“Extraction and Transformation” steps of an Extraction/Transformation/Load
warehouse process. The availability of off-the-shelf CIM/GID compliant wrappers is a key to lowering
application integration and data warehouse deployment and maintenance costs
very significantly.
The GID interfaces support viewing of legacy
application data within the context of a shared model such as the CIM. The GID interfaces take full advantage of the fact
that the CIM is more than just a collection of related attributes – it is a
unified data model. Viewing data in a CIM context helps eliminates manual
configuration and provides a means for a power system engineer to understand
how enterprise data is organized and accessed. The GID interfaces allow legacy data to be exposed
within a power system oriented context. This makes data more understandable and
“empowers the desktop” by enabling power system engineers to accomplish many
common configuration tasks instead of having to rely on IT personnel.
The GID interfaces support viewing of legacy
application data within the context of a shared model such as the CIM. The GID interfaces take full advantage of the fact
that the CIM is more than just a collection of related attributes – it is a
unified data model. Viewing data in a CIM context helps eliminates manual
configuration and provides a means for a power system engineer to understand
how enterprise data is organized and accessed. The GID interfaces allow legacy data to be exposed
within a power system oriented context. This makes data more understandable and
“empowers the desktop” by enabling power system engineers to accomplish many
common configuration tasks instead of having to rely on IT personnel.
Namespaces
The GID interfaces specify two related mechanisms.
The first specifies a programmatic interface that a component or component
wrapper must implement. The second specifies how a populated information model
such as the CIM (the power system class metadata specified in the information
model as well as the related instances) is exposed via the programmatic
interface. The later concept is embodied in the term “namespace”.
A namespaces can
include a complex set of inter related metadata and related instance data. In this case, the namespace contains a “mesh
network” or “lattice” of nodes as shown in Figure
19. In other
words, there is more than one path between any two nodes so it is hard or
impossible to say there is a top or bottom.
The display of all of an unpopulated (just object types) or populated
(including object instances) CIM provides two examples mesh networks since many
CIM classes have many associations to different nodes.

Figure
‑19 Example of a Full Mesh type of Namespace
The TC57 standard
namespaces provide an agreement on how to communicate CIM based hierarchies
via an interface that supports namespace browsing such as the GID and supply a utility specific way (CIM
based) of viewing and configuring the exchange of data. That is, the TC 57 standard namespaces
provide a restricted means for exposing the CIM schema and instance data an
application processes.
Three hierarchical
namespaces are standardized in 61970. They are:
·
TC57PhysicalModel
·
TC57ClassModel
·
TC57ISModel
The
TC57PhysicalModel is a tree that orders power system related instance data in
accordance to how it is contained from a physical perspective. Companies contain
sub control areas; sub control areas contain substations, etc. The idea is that
a power system engineer can find a breaker without having to remember a
potentially convoluted or inconsistent naming scheme as shown below.

Figure
‑20 Example TC57PhysicalNamespace
The TC57ClassModel
consists of a tree that orders power system related instance data in accordance
to object types. Viewing data is this way is often most convenient for example
when one wants to access all protective relays for example.

Figure
‑21 Example TC57ClassNamespace
The TC57ISModel
namespace is associated with the Generic Eventing and Subscription (GES) interface, the standard interface for
publishing and subscribing described below. The tree allows an application to
describe what message types (application data schema) it publishes as well as
the content of each message type.

Figure
‑22 Example TC57ISNamespace
The use of namespaces
This section
describes how a namespaces can be used at an application interface to make
utility data more understandable and usable. For example consider the diagram
below:

Figure ‑23 Traditional view of
utility data
Figure 23 shows how data is often presented by a typical legacy
application. In this case customer data is presented by an application as a
flat set of records without much information about how customers relate to
information modeled in the CIM such as network topology or maintenance history.
However, if one is interested in correlating the reliability of power delivered
to customer to repair records or a network element such as a distribution
feeder for example, then it is useful to be able to put customer records in the
context of the model. The generic interfaces provide a standard way of exposing
data such as customer records within a namespace, in this case the
TC57PhysicalModel as illustrated in Figure
24:

Figure
‑24 Customer data within a CIM Network View
The GID interfaces provide the capability to
discover the metadata and instance data a server exposes via browsing. However, browsing a server’s complete
namespace may consume a large amount of time. For example, consider a namespace
deployed at a large utility. If one
counts all the measurements in the namespace, the number might exceed one
million. The number possible paths to
these measurements can be an order of magnitude more. This can significantly degrade the client
user experience. It is not efficient to
individually discover each measurement by browsing the namespace. Rather, it
would be better if a client that wishes to subscribe to measurement data
updates could determine the locations (paths from a hierarchical namespace root
to destination) of each measurement in a more efficient way. But how can this be done when there is no
standard way of naming each measurement point that indicates where a
measurement occurs in a power system model.
The solution is provided by the employment of a known common information
model such as the CIM and a standard namespace such as the TC57PhysicalModel
namespace.
Consider the
simple namespace illustrated in Figure
25. In this
example with regard to metadata, it is possible for a company to own or operate
a device and devices can have measurements associated with them. With regard to instance data, Eastern
Electric is a company that owns TransformerABC that has a temperature
measurement called Point7.

Figure
‑25 Example Full Mesh Namespace
From this full
mesh namespace, at least two different hierarchical namespaces could be
constructed: one that specifies “company owns devices which have temperature
measurements” and another that specifies “company operates devices which have
temperature measurements”. Since both
are possible it is impossible for an off the shelf client application to
quickly discover the paths from root to every measurement for a large full mesh
information model. On the other hand, if
the client can assume a known hierarchy say “company owns devices which have
temperature measurements”, then the client can perform a very limited number of
queries to discover all the paths to all measurements. In this very simple example, a client need
only query twice once configured with the company name. In the case of the CIM, agreement on the
inclusion of only a limited set of associations that can be traversed can
dramatically improve the user wait time for a client discovering measurements
in a large namespace.
Another example of
the use of the TC57Namespaces consists of the possibility to completely
automate SCADA data client subscription from a TC57Namepace compliant SCADA
server if the client application can import the complete model from a power
system model provider such as an EMS. In this case, a client has the capability
to automatically build the paths to all the measurements in SCADA Server. The
server side of this use case has been tested during the EPRI sponsored CIM/GID Interoperability testing.
An additional
benefit of providing customer data in a standard namespace is that off the
shelf components can be created independently of individual customers
requirements. Such standardization is necessary if one hopes to foster a market
for off the shelf applications.
The Generic Interfaces
Rather than
inventing new interfaces, the IEC chose to leverage OPC - a set of widely deployed de facto standard
interfaces frequently used in the process control industry and supported by
close to 1000 vendors. Three out of four of the IEC interfaces incorporate the
equivalent the OPC interface. However, since the OPC interfaces were originally based on
Microsoft specific technology, the IEC also decided to leverage cross platform
versions of the OPC interfaces standardized in the Object
Management Group (OMG). The OMG is a software standards consortium
consisting of all major software vendors. The OPC versions of the IEC interfaces are used when
deploying COM, .Net or Web Services based interface technology so that the
hundreds of OPC clients available off the shelf from many
vendors are GID compliant today. On the other hand, the OMG version of the GID is use to define the CORBA, Java, or C
Language interfaces. The diagram below illustrates the lineage
between the WG 13, OMG, and OPC interfaces.

Figure
‑26 Interface Lineage
While for the sake
of convenience, this document will use the IEC names when discussing the
Microsoft and non-Microsoft varieties of the interfaces, it should be noted
that both the OMG and OPC variants of the interfaces are GID compliant.
High Speed Data Access
The High Speed
Data Access (HSDA) interface was designed to handle the unique requirements of
exchanging high throughput data. For example, a larger SCADA system might need
exchange measurements at a rate exceeding 5,000 points per second. For these
high performance situations, it is necessary to deploy an interface optimized
for throughput. The tradeoff for achieving higher throughput is that HSDA is a
small amount more time consuming to configure. HSDA supports the TC57 namespaces
so that power system engineers can access measurement data in a user friendly
way. The diagram below illustrates how HSDA might be deployed.

Figure
‑27 Example Of The Use Of The High Speed Data Access
Interface
Time Series Data Access
The Time Series Data Access (TSDA) interface
is designed for the exchange of arrays of data where each array contains the
values of a single data point over time. The mechanics of efficiently passing
these arrays requires a separate interface. TSDA supports the TC57
namespaces so that power system engineers can access time series data in a user
friendly way.

Figure
‑28 Example Of The Use Of The Time Series Data Access
Interface
Generic Data Access
The Generic Data
Access (GDA) interface specification is the one standard interface that was not
created from a previously existing OPC specification. GDA provides Read/Write access to data typically in a database. It is similar in functionality to ODBC but is platform and schema
neutral. The GDA more effectively leverages the work of NERC’s Security
Coordinator’s Model Exchange Format (CIM XML). Using the GDA, a user accesses
the data via the CIM terminology of classes, attributes, and relationships.
Unlike ODBC, the GDA interface is independent of how data may be physically
stored in the database. As a result, it is an ideal way for vendors to expose
their data in a CIM compliant way that is database schema neutral so to enable
the construction of a data warehouses as shown below:

Figure
‑29 CIM/GID Based Data Warehouse
GDA includes the
ability to notify clients when data has been updated in the server. This
functionality provides an important piece of the puzzle when constructing an
infrastructure that enables a single point of update for model changes.
Generic Eventing and Subscription
The Generic
Eventing and Subscription (GES)
interface specification is designed to be the primary mechanism for application
integration. The GES provides an interface by which applications
can publish and subscribe to CIM data. As a publish/subscribe oriented
interface it supplies an ideal vendor-neutral interface for a generic
application integration product such as those from the major IT vendors.
In addition to
just providing a way for applications to publish or subscribe to data, the GES interface takes maximum advantage of CIM as
presented in a TC57 Namespace. That is, GES provides a power system oriented
mechanism for data subscription configuration that power system engineers can
use. The diagram below illustrates a sample TC57PhysicalNamespace. The namespace
would typically be displayed in a subscription configuration graphical user
interface (GUI). By displaying a view of the power system model in a message
subscription configuration GUI, the user can set up subscriptions without
having to know the often complex subscription configuration script syntax used
by the generic application integration tool. Off the shelf generic integration
tools know nothing about power system models. By providing a power system
specific user-friendly layer on top of the generic application integration
tool, power system engineers can do things such as subscribe to a daily report
without requiring the assistance of an information technology professional.

Figure
‑30 TC57Namespace Used As A Subscription Topic Tree
Using the example
namespace above, the user could subscribe to data related to a company, to just
a particular substation, or just a set of devices in a substation – potentially
all done via a user friendly GUI.
Besides providing
a context for subscribing to messages, the CIM provides a data dictionary for GES messages. In fact, WG 14 has defined a set
of message definitions for common utility operational business processes. The
figure below illustrates the process of defining messages from the CIM.

Figure
‑31 Model Driven Message Definition
This section describes issues related to energy market
Energy Market related technologies: how they are used in industry and how they
fit into the IntelliGrid Architecture. As with
previous sections, this section does not exhaustively discuss all energy market
Energy Market related technologies.
Instead it highlights several of the more important issues related to
technologies that can be applied to an energy market and several technologies
that provide the flexibility and strength to satisfy important utility
requirements. As in the previous
sections, we are guided by the high level requirements of information discovery
and flexibility.
Since the first attempts at an Energy Market
in the late 90’s, utilities have deployed a number of pilot and tactical
solutions. While most of these projects
made significant contribution to documenting business processes, from a
technological perspective, most if not all of these solutions were not
considered ideal. This is not surprising
as Energy Market technology in general not considered mature or enjoys
widespread support by users and vendors.
For the retail market, the limitations are
clear. Many utility retail customers are
not familiar with using the Internet for paying bills or interaction with
customer service. While it is likely
that in the future, Energy Market will become more widely used for retail
transactions, it is not expected that retail energy transaction will be adopted
at a greater pace. Furthermore, the
technologies used for generic retail will likely dominate utility retail
transactions if only to minimize the cost of installing a utility retail Energy
Market infrastructure.
While significant cost reduction will be
derived from market wide data exchange standards that specify message format
and flow, the fact that markets differ means that data exchange standards alone
cannot optimally reduced costs. It is
only the combination of market specific data exchange standards combined with
common information models and technologies that can provide the preconditions
required for the creation “off the shelf” software. The approach maximally meets the needs of
utilities and establishes a methodology and architecture for standard market
design.
Utilities may be more successful in
determining the pace at which the wholesale Energy Market progresses. In the wholesale market, utilities can have a
significant impact on forcing convergence on a particular set of
technologies. This in turn will allow
vendors to deliver product that does not need to be developed for a particular
market but instead is customizable via configuration. The use of software that is more “off the
shelf” should greatly improve the return on investment and greatly reduce the
risk associated with these complex Energy Market projects.
eTagging
and ebXML
In July 1997, North American Electric
Reliability Council (NERC) implemented a process of electronically documenting
an energy transaction via the Internet. The process is formally called the
Transaction Information System (TIS) but is more commonly referred to as Electronic
Tagging (E-Tag). A tag is an electronic documentation of an energy transaction
that requires coordination of and approval from all operating entities involved
- origin, intermediate, and destination. The transaction is described within
the tag as an "energy schedule" to be transferred over a prescribed
path for a specific duration and time frame. Tags are transmitted via a
computer-to-computer, point-to-point method over the Internet in order that
Transmission Line Loading Relief (TLR) can be more readily managed. The
information contained in the tag is generally considered to be confidential,
particularly in the hourly market. Tagging is not scheduling. Tagging is the
communication of information necessary to perform security evaluations and of a
desire to schedule.
In 2002, ERCOT replace a manual file transfer
based solution with an electronic messaging based system based on ebXML.
Similarly to eTagging, the ERCOT solution is
based on fixed messaging and fixed business processes. While both these solutions met the tactical
goals of the projects, there applicability to a generic solution that can be
applied to a variety of underlying transport technologies is limited. However,
if we accept the above analysis, the question then becomes does eTagging or
ebXML support all the essential ingredients for flexible interoperability. One could conclude that traditional fixed
Energy Market technologies such as eTagging lack an infrastructure for data
semantics and thus a way to configure them.
The following paragraphs describe ebXML’s support for the discovery of
the meaning of data as well as its architecture to support limited semantic
discovery and exchange.
The difference between the approach taken by
ebXML and something like WG 13’s approach can be described as a document-based
approach versus a knowledge-based approach.
A document-based approach is fundamentally based on the concept that
interaction between components can largely be standardized via the agreement on
the definition of a set of freestanding documents. For example, if I want to connect an energy
trader system with an ISO/RTO for the purpose of exchanging schedules, then I
define a set of documents that describe a schedule. The key here is that I am not defining a
knowledge system; I am describing an actual exchange. It should be noted that it may be possible to
abstract away some of the specifics of particular exchanges and come up with a
set of base documents that get reused.
In fact this is what ebXML does.
That is, ebXML allows a designer to specify a set of document for
exchange that can be based on a set of reusable document fragments.
The registry of ebXML supports the definition
and exchange of these documents and document fragments, but does not support
the notion of a unified information model.
This knowledge-based approach assumes that document definitions are
somewhat unknowable at design time and instead is based on an approach whereby
components can more dynamically create documents definitions. In this case, a document is just one possible
view of the combined and unified knowledge base.
To provide a TC 57 example, WG 10 - 12 is only defining a minimal set of
predefined message exchange patterns.
However, a high degree of interoperability is expected only in the
presence of a shared service and data models.
Similarly, WG 13’s approach assumes that is easier to agree on what a
breaker is for example as opposed to trying to agree on what information about
a breaker is exchange by two components during an generalized exchange. Put another way, WG 13’s approach assumes
that it is easier to agree on a more application neutral information model as
opposed to a business process. To provide a more relevant example, it may be
impossible for WG 16 to prescribe the definition of a schedule exchange
(including what documents are passed back and forth) for all European markets
but it might be possible to describe what schedule is and becomes especially
useful if one relates a schedule to other utility data in a unified model that
includes the transmission system, generators, and loads.
The advantage of this approach is that the
infrastructure is able to handle a greater number of exchange
particularities. For example, different
trading markets will have different business processes associated with
them. Each business process may package
information very differently. An
information model that is constructed independently of any one market can be used
to avoid disagreements based on parochial points of view. The ebXML registry is
not designed to maintain a unified information model that is independent to any
one exchange. The ebXML registry only
contains process and document definitions.
It is very difficult to create a document or set of documents that can
capture the complexity of an information model such as the CIM. One needs a more powerful architecture and
ebXML cannot easily provide support for this.
CME
Recently, a group of RTO’s and ISO’s formed a
working group called the ISO/RTO Standards Collaborative and also includes
people from suppliers of energy market transaction servers. The first phase of their work has included
the development of a draft set of CIM extensions, CIM Market Extensions (CME),
for internal ISO/RTO data exchange related to Security Constrained Unit
Commitment. Data modeling associated
with Locational Marginal Pricing and Economic Dispatch is also included. The significance of this work is that it
facilitates seamless integration of an energy market transaction service with
operational systems when messages between the two are based on CME.
EbXML
There are two important limitations of ebXML:
Limitations of its technical approach and limitations of its market
acceptance. With regard to the technical
approach, we need to step back somewhat and examine the essential ingredients
for more complete interoperability. This
analysis is based on experience gained in standardization efforts that have
occurred in IEC TC 57 WG 10 – 12, 13, and 14 over approximately the last six or
seven years.
Lastly, it is expected that ebXML faces
significant if not overwhelming competition in the market place. Many analysts have suggested that the WS-I
has a stronger market position because all the major software vendors back it.
While ebXML has some vendor support and is more mature in several specific
technologies, the architectural assumptions of ebXML are more restricted in the
case of a semantic infrastructure. For
many important standards such as business process modeling, security, reliable
messaging, registry interface, ebXML technology competes head on with standards
being promoted by WS-I.
In light of the above discussion, it is
suggested that ebXML only be used as one of the possible technology profiles
adopted by WG 16. While ebXML, because
of its slightly more mature technology stack, could be a better choice for a
project in the short term, it is not clear if ebXML will evolve to support a
knowledge-based architecture and in which direction the market is heading.
|
